Variable และ Storage binding
ตัวแปรจะผูกมัดกับตำแหน่งในเมมโมรี ในระหว่างการประมวลผล
ประเภทตัวแปรเมื่อพิจารณาลักษณะการผูกมัดไปยังเมมโมรี สามารถจำแนกได้ดังนี้
1. Static variable ตัวแปรพวกนี้จะผูกมัดไปยังตำแหน่งในเมมโมรีในช่วง Load time เช่น ตัวแปรที่กำหนดด้วยคำว่า static เช่น ในภาษา C
static int c;
การใช้งานตัวแปร static ในฟังก์ชั่น main และ ในฟังก์ชั่นอื่นๆ จะมีความแตกต่างกัน แต่การผูกมัดจะกระทำใน load time ก่อน runtime
2. Stack-Dynamic variable คือตัวแปรที่ถูก allocated ในช่วง run time เช่น การใช้งานตัวแปรปกติในภาษา c เช่น int c;
3. Explicit Heap-Dynamic Variables ตัวแปรผูกมัดกับเมมโมรีที่มีการจัดการโครงสร้างการเข้าถึงในลักษณะ Heap เช่นในภาษา Java คำสั่ง new คือคำสั่งในการ allocate เมมโมรีสำหรับ Object หรือใน C++ เช่นเดียวกัน Allocation และ Deallocation จะกำหนดด้วยคำสั่งในภาษาการโปรแกรม (่Java มี garbage collection ซึ่ง deallocation ทำอัตโนมัติเมื่อไม่มีการเรียกใช้ Object แล้ว)
4. Implicit Heap-Dynamic Variables ตัวแปรจะผูกมัดไปยังตำแหน่งในเมมโมรีเมื่อมีการกำหนดค่า (การทำ assignment) เช่นในภาษาประเภท Dynamic typing (เข่น PHP, JavaScript) ที่ไม่ต้องประกาศไทป์ของตัวแปรก่อนการใช้งาน จะเกิดการทำ allocation เมื่อรันถึงคำสั่งที่มีการกำหนดค่าให้กับตัวแปร
Wednesday, July 22, 2015
Subprogram
Subprogram
ในหลักการภาษาการโปรแกรมนั้น Subprogram หมายถึงส่วนของโปรแกรมที่มีการเรียกใช้ซ้ำ มี 2 ประเภท คือ
1. Function คือ subprogram ซึ่งจะมีการรีเทิร์นค่าข้อมูล
2. Procedure คือ subprogram ซึ่งไม่มีการรีเทิร์นค่ากลับ
เมื่อรันโปรแกรมและมีการเรียก Subprogram จะทำให้การประมวลผลของโปรแกรมหลักหยุดชั่วคราว เพื่อเข้าไปประมวลผลใน Subprogram ซึ่งจะมีการสร้างพื้นที่ในเมมโมรีเพื่อจัดการกับโค้ดและข้อมูลของ Subprogram ดังภาพ พื้นที่ส่วนแรกเก็บโค้ดของ Subprogram และพื้นที่ส่วนถัดไปเก็บ data ที่มีการประมวลผลใน Subprogram ซึ่งเรียกว่า Activation record (ดูภาพ 10.2)


ในหลักการภาษาการโปรแกรมนั้น Subprogram หมายถึงส่วนของโปรแกรมที่มีการเรียกใช้ซ้ำ มี 2 ประเภท คือ
1. Function คือ subprogram ซึ่งจะมีการรีเทิร์นค่าข้อมูล
2. Procedure คือ subprogram ซึ่งไม่มีการรีเทิร์นค่ากลับ
เมื่อรันโปรแกรมและมีการเรียก Subprogram จะทำให้การประมวลผลของโปรแกรมหลักหยุดชั่วคราว เพื่อเข้าไปประมวลผลใน Subprogram ซึ่งจะมีการสร้างพื้นที่ในเมมโมรีเพื่อจัดการกับโค้ดและข้อมูลของ Subprogram ดังภาพ พื้นที่ส่วนแรกเก็บโค้ดของ Subprogram และพื้นที่ส่วนถัดไปเก็บ data ที่มีการประมวลผลใน Subprogram ซึ่งเรียกว่า Activation record (ดูภาพ 10.2)

Nested subprogram หมายถึง Subprogram ที่ซ้อน Subprogram บางภาษาเอื้อในการเขียนโปรแกรมในลักษณะนี้ เช่น JavaScript
function sub1() {
var x;
function sub2() {
alert(x); // Creates a dialog box with the value of x
};
function sub3() {
var x;
x = 3;
sub4(sub2);
};
function sub4(subx) {
var x;
x = 4;
subx();
};
x = 1;
sub3();
};
ภาษาการโปรแกรมต้องกำหนดวิธีการเรียก Subprogram ในกรณีที่เป็น Nested subprogram ภาษาส่วนใหญ่จะยอมให้เรียก Subprogram ย่อยภายใน Nested subprogram เมื่อ Nested subprogram ถูกเรียกก่อน เช่น Main program ต้องเรียก sub1( ) ก่อน จึงจะสามารถเรียก Subprogram อื่นๆภายใน
และภายใน Nested subprogram นั้นอาจมีการรเรียก Subprogram ย่อยภายใน ซึ่งจะต้องพิจารณา Reference environment ตามไปด้วย
เมื่อมีการเรียก Subprogram ทำงาน สิ่งที่ต้องคำนึงถึงได้แก่
1. Referencing environment ในคำสั่ง/บรรทัดหนึ่งๆ ใน Subprogram จะสามารถมองเห็น(ใช้งาน) ตัวแปรใดบ้าง?
2. Parameter passing mode เป็นอย่างไร ?
3. เมื่อมีการเรียก Subprogram แล้วการจัดการ Scope ของ Subprogram จะเป็นอย่างไร ?
ในกรณี Nested subprogram ต้องพิจารณา Environment ของ Subprogram ที่ถูกเรียก ซึ่งพิจารณาจาก 3 ลักษณะ
- Shallow binding เมื่อมีการเรียก subprogram แล้ว environment ของ subprogram ที่ถูกเรียกจะเป็น Environment ของ subprogram ที่เรียก เช่น sub4(sub2) environment ของ sub2 คือ Environment ของ sub4 ดังนั้น เมื่อ alert ทำงานจะแสดงผลลัพธ์ x ของ sub4
- Deep binding เมื่อมีการเรียก subprogram แล้ว environment ของ subprogram ที่ถูกเรียกจะเป็น Environment ตาม definition ของ subprogram เช่น sub4(sub2) environment ของ sub2 คือ sub1 เนื่องจากมันอยู่ภายใต้ sub1 ดังนั้น alert จะแสดง x ของ sub1
- Adhoc binding เมื่อมีการเรียก subprogram แล้ว environment ของ subprogram ที่ถูกเรียกจะเป็น Environment ของตำแหน่งที่เรียก subprogram เช่น sub4(sub2) นั้นอยู่ใน sub3 ดังนั้น sub2 จะแสดงค่า x ของ sub3
Coroutine
Coroutine คือ subprogram ประเภทหนึ่ง ที่สามารถเข้าถึงได้หลายทางหรือมี Multiple entry point การเรียก coroutine จะเกิดความสัมพันธ์ระหว่าง subprogram ในลักษณะ Master-slave คำสั่ง resume ทำให้เกิดการเรียก subprogram โดยเข้าถึง subprogram ในตำแหน่งคำสั่งถัดจากคำสั่งที่ออกจาก subprogram จากการเรียกครั้งก่อน (ในกรณีเรียก subprogram ครั้งแรกจะเป็นการเรียกไปยังจุดเริ่มต้นของ subprogram)
sub co1(){
. . .
resume co2();
. . .
resume co3();
. . .
resume co2();
}
sub co2(){
. . .
resume co1();
...........
}
sub co3(){
. . .
resume co1();
}

Monday, July 20, 2015
Scope และ Referencing Environment
Scope และ Referencing Environment
Scope การใช้งานตัวแปร คือ ขอบเขตที่สามารถใช้งานตัวแปรได้
การกำหนด Scope จำแนกได้ 2
ลักษณะ
1. Static Scoping ตัวแปรจะมีขอบเขตสัมพันธ์กับ Unit ที่ครอบตัวแปร การใช้งานตัวแปรสามารถทำได้หลังจากมีการประกาศ (declare) ตัวแปรแล้ว (สำหรับภาษาที่ต้องประกาศไทป์ก่อนใช้)
หรือในบางภาษาที่ไม่ต้องประกาศไทป์ก่อนใช้งาน ก็จะสามารถเรียกใช้ได้ทันทีตั้งแต่บรรทัดที่มีการใช้งานตัวแปร
เช่น ใน C มีการจัดการแบบ Static scoping
1. | #include <stdio.h>
2. | int x;
3. | void main( )
4. | {
5. | void myfunction(int a, int b);
6. | int y;
7. | ...
8. | }
9. | void myfunction (int m, int n)
10.| {
11.| int o;
12.| ...
13.| }
Unit หรือขอบเขต ในโปรแกรมสามารถพิจารณาได้ดังนี้
1. ขอบเขตครอบคลุมทั้งโปรแกรม
2. ขอบเขตภายในฟังก์ชั่น main
3. ขอบเขตภายในฟังก์ชั่น myfunction
ตัวแปร x ในภาษา C จึงสามารถมองเห็นได้จากทุกๆส่วนของโปรแกรม หรือเราจะรู้ตามกฎการเป็น Global variable ในภาษา C ที่อะไรประกาศเหนือฟังก์ชั่น main จะมองเห็นได้จากทุกส่วนของโปรแกรม main และ subfunction
ตัวแปร a และ b เป็นเพียงตัวแปรที่ประกาศตามข้อกำหนดของฟังก์ชั่นไม่สามารถใช้งานได้
ตัวแปร y ประกาศในฟังก์ชั่น main จึงสามารถเรียกใช้ได้ภายในฟังก์ชั่น main โดยนับตั้งแต่คำสั่งถัด (หรือบรรทัดถัดไป) หลังประกาศตัวแปรแล้ว แต่ตัวแปร y ไม่สามารถมองเห็นได้ในฟังก์ชั่น
ตัวแปร m, n และ o ถือว่าเป็นตัวแปรที่ประกาศในฟังก์ชั่น ดังนั้นสามารถใช้งานได้ในเวลารันที่มีเรียกฟังก์ชั่นเท่านั้น และจะเรียกตัวแปร o ได้ในบรรทัดถัดไป (หลังบรรทัดที่ประกาศ)
ข้อสังเกต
1. การจัดการขอบเขตการใช้งานของตัวแปรในลักษณะนี้มักจะกำหนดให้ตัวแปรที่ประกาศใน Unit ที่ให,่กว่า สามารถมองเห็นได้ใน Unit ที่เล็กกว่า เช่น กรณีตัวแปร x เป็นต้น
2. เมื่อตัวแปรมีขอบเขตของตัวแปร เราจะเรียกว่าเป็น Local variable ของ Unit นั้น ส่วนตัวแปรอื่นๆที่อยู่นอกจาก Unit นั้น เราจะเรียกว่า Nonlocal variable
3. บางภาษาการโปรแกรมกำหนดให้การประกาศตัวแปรต่างๆ ต้องทำก่อนคำสั่งอื่นๆ โดยไม่ยอมให้มีการประกาศในระหว่างโปรแกรม แต่บางภาษาอนุญาตให้มีการประกาศได้ในตำแหน่งใดก็ได้ของโปรแกรม เพียงแค่กำหนดขอบเขต เช่นในภาษา C ใช้เครื่องหมาย {...} กำหนดขอบเขตของตัวแปร
{
int i;
i = 88;
j = 99;
printf("(2) i: %d, j: %d\n", i, j);
}
2. Dynamic Scoping
การจัดการขอบเขตการใช้งานของตัวแปรขึ้นกับลำดับการเรียกฟังก์ชั่น
สมมติภาษา Anynomous มีการจัดการแบบ Dynamic Scoping
1. |int b = 5;
2. |int foo( )
3. |{
4. | int a = b + 5;
5. | return a;
6. |}
7. |int bar( )
8. |{
9. | int b = 2;
10.| return foo( );
11.|}
12.|int main( )
13.|{
14.| foo( );
15.| bar( );
16.| return 0;
17.| }
บรรทัดที่ 12 เมื่อมีการรันโปรแกรมฟังก์ชั่น main( ) (สมมติ main ถูกเรียกก่อน) ถูกเรียกก่อน
ตัวแปร b จะถูกมองเห็นเป็นอันดับแรก
บรรทัดที่ 14 เมื่อเรียกฟังก์ชั่น foo จะมองเห็นตัวแปร a และ b ซึ่ง a = 10 และ b = 5 แล้วรีเทิร์นออกจากฟังก์ชั่นไปบรรทัดที่ 15
บรรทัดที่ 15 จะมองเห็นตัวแปร a และ b ดังนั้นเมื่อเรียกฟังก์ชั่น bar การประกาศ b ขึ้นมาใหม่จะเป็น b อีกตัวแปรหนึ่ง ซึ่งมีค่าเท่ากับ 12 และยังคงมี b = 5 ในสแตก แต่ไม่สามารถเรียกใช้ b = 5 ภายใน bar( บรรทัดที่ 9-11) มีการเรียก foo อีกครั้ง (จากการเรียก return ) จะเกิด a อีกตัว (บรรทัดที่ 4) ซึ่งตอนนี้ a มีค่าเท่ากับ 7 (จาก b = 2 ใน bar) ส่งค่ากลับคือ 7 แล้วในบรรทัดที่ 10 จะส่งค่ากลับคือ 7 แล้วรีเทิร์นไปทำงานที่บรรทัดที่ 16

13.|{
14.| ...
15.| foo( );
16.| ......
17.| bar( );
18.| ......
19.| return 0;
20.| }
ข้อสังเกต
ยังต้องพิจารณาจากขอบเขตของตัวแปรจาก Unit ที่ตัวแปรอยู่เช่นเดียวกับ Static scoping แต่พิจารณาเพิ่มเมื่อมีการเรียกฟังก์ชั่น
Referencing environment
Referencing environment หมายถึง ชื่อตัวแปรต่างๆที่มองเห็นได้จากบรรทัดที่กำลังประมวลผล
จากโค้ดที่ยกตัวอย่างบนสุด สมมติรันโปรแกรมมาถึงบรรทัดที่ 6 ณ บรรทัดนั้นจะสามารถมองเห็นตัวแปร y และตัวแปร x ได้ ซึ่งทั้งสองตัวแปรคือ Referencing environment ของการประมวลผล ณ ขณะนั้น
หากรันโค้ดมาถึงบรรทัดที่ 11 Referencing environment คือ ตัวแปร m, n, o และ x พารามิเตอร์ m และ n ถือว่าเป็น local variable ของฟังก์ชั่น
Scope การใช้งานตัวแปร คือ ขอบเขตที่สามารถใช้งานตัวแปรได้
การกำหนด Scope จำแนกได้ 2
ลักษณะ
1. Static Scoping ตัวแปรจะมีขอบเขตสัมพันธ์กับ Unit ที่ครอบตัวแปร การใช้งานตัวแปรสามารถทำได้หลังจากมีการประกาศ (declare) ตัวแปรแล้ว (สำหรับภาษาที่ต้องประกาศไทป์ก่อนใช้)
หรือในบางภาษาที่ไม่ต้องประกาศไทป์ก่อนใช้งาน ก็จะสามารถเรียกใช้ได้ทันทีตั้งแต่บรรทัดที่มีการใช้งานตัวแปร
เช่น ใน C มีการจัดการแบบ Static scoping
1. | #include <stdio.h>
2. | int x;
3. | void main( )
4. | {
5. | void myfunction(int a, int b);
6. | int y;
7. | ...
8. | }
9. | void myfunction (int m, int n)
10.| {
11.| int o;
12.| ...
13.| }
Unit หรือขอบเขต ในโปรแกรมสามารถพิจารณาได้ดังนี้
1. ขอบเขตครอบคลุมทั้งโปรแกรม
2. ขอบเขตภายในฟังก์ชั่น main
3. ขอบเขตภายในฟังก์ชั่น myfunction
ตัวแปร x ในภาษา C จึงสามารถมองเห็นได้จากทุกๆส่วนของโปรแกรม หรือเราจะรู้ตามกฎการเป็น Global variable ในภาษา C ที่อะไรประกาศเหนือฟังก์ชั่น main จะมองเห็นได้จากทุกส่วนของโปรแกรม main และ subfunction
ตัวแปร a และ b เป็นเพียงตัวแปรที่ประกาศตามข้อกำหนดของฟังก์ชั่นไม่สามารถใช้งานได้
ตัวแปร y ประกาศในฟังก์ชั่น main จึงสามารถเรียกใช้ได้ภายในฟังก์ชั่น main โดยนับตั้งแต่คำสั่งถัด (หรือบรรทัดถัดไป) หลังประกาศตัวแปรแล้ว แต่ตัวแปร y ไม่สามารถมองเห็นได้ในฟังก์ชั่น
ตัวแปร m, n และ o ถือว่าเป็นตัวแปรที่ประกาศในฟังก์ชั่น ดังนั้นสามารถใช้งานได้ในเวลารันที่มีเรียกฟังก์ชั่นเท่านั้น และจะเรียกตัวแปร o ได้ในบรรทัดถัดไป (หลังบรรทัดที่ประกาศ)
ข้อสังเกต
1. การจัดการขอบเขตการใช้งานของตัวแปรในลักษณะนี้มักจะกำหนดให้ตัวแปรที่ประกาศใน Unit ที่ให,่กว่า สามารถมองเห็นได้ใน Unit ที่เล็กกว่า เช่น กรณีตัวแปร x เป็นต้น
2. เมื่อตัวแปรมีขอบเขตของตัวแปร เราจะเรียกว่าเป็น Local variable ของ Unit นั้น ส่วนตัวแปรอื่นๆที่อยู่นอกจาก Unit นั้น เราจะเรียกว่า Nonlocal variable
3. บางภาษาการโปรแกรมกำหนดให้การประกาศตัวแปรต่างๆ ต้องทำก่อนคำสั่งอื่นๆ โดยไม่ยอมให้มีการประกาศในระหว่างโปรแกรม แต่บางภาษาอนุญาตให้มีการประกาศได้ในตำแหน่งใดก็ได้ของโปรแกรม เพียงแค่กำหนดขอบเขต เช่นในภาษา C ใช้เครื่องหมาย {...} กำหนดขอบเขตของตัวแปร
{
int i;
i = 88;
j = 99;
printf("(2) i: %d, j: %d\n", i, j);
}
2. Dynamic Scoping
การจัดการขอบเขตการใช้งานของตัวแปรขึ้นกับลำดับการเรียกฟังก์ชั่น
สมมติภาษา Anynomous มีการจัดการแบบ Dynamic Scoping
1. |int b = 5;
2. |int foo( )
3. |{
4. | int a = b + 5;
5. | return a;
6. |}
7. |int bar( )
8. |{
9. | int b = 2;
10.| return foo( );
11.|}
12.|int main( )
13.|{
14.| foo( );
15.| bar( );
16.| return 0;
17.| }
บรรทัดที่ 12 เมื่อมีการรันโปรแกรมฟังก์ชั่น main( ) (สมมติ main ถูกเรียกก่อน) ถูกเรียกก่อน
ตัวแปร b จะถูกมองเห็นเป็นอันดับแรก
บรรทัดที่ 14 เมื่อเรียกฟังก์ชั่น foo จะมองเห็นตัวแปร a และ b ซึ่ง a = 10 และ b = 5 แล้วรีเทิร์นออกจากฟังก์ชั่นไปบรรทัดที่ 15
บรรทัดที่ 15 จะมองเห็นตัวแปร a และ b ดังนั้นเมื่อเรียกฟังก์ชั่น bar การประกาศ b ขึ้นมาใหม่จะเป็น b อีกตัวแปรหนึ่ง ซึ่งมีค่าเท่ากับ 12 และยังคงมี b = 5 ในสแตก แต่ไม่สามารถเรียกใช้ b = 5 ภายใน bar( บรรทัดที่ 9-11) มีการเรียก foo อีกครั้ง (จากการเรียก return ) จะเกิด a อีกตัว (บรรทัดที่ 4) ซึ่งตอนนี้ a มีค่าเท่ากับ 7 (จาก b = 2 ใน bar) ส่งค่ากลับคือ 7 แล้วในบรรทัดที่ 10 จะส่งค่ากลับคือ 7 แล้วรีเทิร์นไปทำงานที่บรรทัดที่ 16
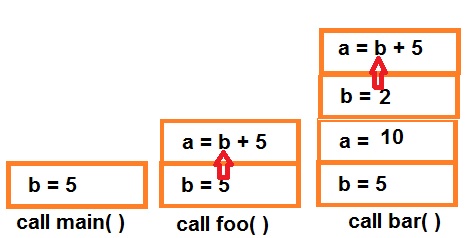
ถ้าแก้ไขโค้ดใหม่ (ยังคงเป็นภาษา Anynomous ไม่ใช่ภาษา C!!)
12.|int main( )13.|{
14.| ...
15.| foo( );
16.| ......
17.| bar( );
18.| ......
19.| return 0;
20.| }
บรรทัดที่ 14 จะมองเห็นตัวแปร b
บรรทัดที่ 16 เมื่อเรียก foo แล้วจะเห็นตัวแปร b = 5 และ a = 10
บรรทัดที่ 18 เมื่อเรียก bar แล้วจะเห็นตัวแปร b = 2 และ a = 7
ขอบเขตของตัวแปรขึ้นกับลำดับการเรียกฟังก์ชั่น ไม่ใช่ขอบเขตของ Unit จากภาพด้านบน ยังคงมี a = 10 และ b = 5 ในสแตก แต่การรันโปรแกรมจะไม่สามารถเรียกใช้ตัวแปรเหล่านี้ได้ เพราะถูกบดบังด้วยตัวแปร a และ b ที่เกิดขึ้นล่าสุดจากการประกาศในบรรทัดที่ 4 และ 9 ในการเรียก foo และเรียก bar (ซึ่งเรียก foo ต่อเพื่อรีเทิร์นค่า)
ยังต้องพิจารณาจากขอบเขตของตัวแปรจาก Unit ที่ตัวแปรอยู่เช่นเดียวกับ Static scoping แต่พิจารณาเพิ่มเมื่อมีการเรียกฟังก์ชั่น
Referencing environment
Referencing environment หมายถึง ชื่อตัวแปรต่างๆที่มองเห็นได้จากบรรทัดที่กำลังประมวลผล
จากโค้ดที่ยกตัวอย่างบนสุด สมมติรันโปรแกรมมาถึงบรรทัดที่ 6 ณ บรรทัดนั้นจะสามารถมองเห็นตัวแปร y และตัวแปร x ได้ ซึ่งทั้งสองตัวแปรคือ Referencing environment ของการประมวลผล ณ ขณะนั้น
หากรันโค้ดมาถึงบรรทัดที่ 11 Referencing environment คือ ตัวแปร m, n, o และ x พารามิเตอร์ m และ n ถือว่าเป็น local variable ของฟังก์ชั่น
Sunday, July 19, 2015
Binding และ Binding time
Binding และ Binding time
Binding คือ การผูกมัดสิ่ง 2 สิ่งเข้าด้วยกัน เช่น ไทป์กับตัวแปร โอเปอเรเตอร์กับการดำเนินการ ตัวแปรกับตำแหน่งอ้างอิงในเมมโมรี
Binding เกิดได้ตลอดเวลา อาจพิจารณาเวลาผูกมัดได้หลายเวลา เช่น
1. Language design time
2. Language implementation time
3. Compile time
4. Link time
5. Load time
6. Run time
Language design time
การผูกมัดที่เกิดในช่วงการออกแบบภาษา เช่น การออกแบบชิ้นส่วนต่างๆ (construct) ของภาษา เช่น สัญลักษณ์ตัวดำเนินการแทนการดำเนินการ (+ แทนการบวก, - แทนการลบ เป็นต้น) รูปแบบ Statement (if-else, while, for) ไทป์ต่างๆ
Language implementation time
การผูกมัดที่เกิดในเวลานำไปใช้ เกี่ยวข้องกับการกำหนดรูปแบบของ Precision ของ Floating-point number และ การแสดงในเมมโมรีของ data type ชนิดต่างๆ (ใช่กี่บิต เรียงบิตอย่างไร เลขยกกำลังใช้มาตรฐานอะไร) การจัดการเมมโมรีของโปรแกรม หรือฟงัก์ชั่น การจัดการเมมโมรีของตัวแปร local และ nonlocal การจัดการตรวจจับรันไทม์ error เช่น Overflow
Compile time
การผูกมัดที่เกิดในเวลาคอมไพล์ เช่น การจับคู่ระหว่าง Token กับ Lexeme ในตาราง Symbol table เช่น ตัวแปรกับไทป์ เครื่องหมายดำเนินการกับตัวดำเนินการ หรือการผูกมัดระหว่างตัวดำเนินการกับ Machine code (เช่น + ผูกมัดกับคำสั่ง ADD ของ Machine code รุ่น intel....)
Link time
ในการเขียนโปรแกรมบางครั้งอาจมีการแยกโปรแกรมออกเป็นส่วนๆ แล้วแยกคอมไพล์ ในเวลานี้คือเวลาที่เกิดขึ้นเพื่อนำโค้ดที่ผ่านการคอมไพล์มารวมเข้าด้วยกัน ก่อนที่จะสร้าง Machine code (ซึ่งจะมีเพียงส่วนเดิยวที่สามารถนำไปรันได้) ยกตัวอย่างในภาษา C เราอาจแยกโค้ดเป็นหลายส่วน เมื่อคอมไพล์จะได้ .OBJ แล้วในเวลา Link time คือผููกมัดที่นำ .OBJ มารวมกัน นอกจากนี้แล้วอาจพิจารณาการรวมโค้ดของโปรแกรมเข้ากับโค้ดของ OS เพื่อใช้งาน I/O ได้อีกด้วย
Load time
คือเวลาผูกมัดที่เกิดขึ้นเมื่อ OS โหลดโปรแกรมเข้าไปไว้ในเมมโมรีก่อนรัน ตัวอย่างเช่น การโหลดตัวแปรประเภท Static จะเกิดการผูกมัดไปยัง Physical address ตำแหน่งหนึ่ง ตลอดการรันโปรแกรม
(ดูการใช้งานตัวแปร Static) อะไรก็ตามที่ถูกกำหนดผูกเข้ากับ Physical address เกิดการผูกมัดในเวลา load time เช่น ค่าคงที่ต่างๆเช่นกัน
Runtime
การผูกมัดที่เกิดในเวลารัน เช่น ตัวแปรกับค่าของตัวแปร ตัวแปร (dynamic variable) กับตำแหน่งในเมมโมรี (ซึ่งอาจเปลี่ยนไปได้ตลอดเวลา)
คำสั่งหนึ่งคำสั่งอาจเกี่ยวข้องกับการผูกมัดได้หลายลักษณะ เช่น
int x = 10;
ค่าคงที่ 10 มีการผูกมัดไปยังตำแหน่งในเมมโมรี (อาจอยู่ในรีจิสเตอร์ก็ได้) ในเวลา Load time
ตัวแปร x มีการผูกมัดไปยังไทป์ในเวลาคอมไพล์
ส่วนตัวแปร x จะผูกมัดไปยังตำแหน่งในเมมโมรี (หรือรีจิสเตอร์) ของค่าคงที่ 10 จะรู้ก็ตอนรันไทม์ (ไม่รู้ตอนคอมไพล์เพราะช่วงคอมไพล์ x ยังไม่ผูกมัดไปยัง Physical address แต่อาจผูกไป virtual address ก็ได้ถ้าภาษากำหนดขึ้นมาชั่วคราว)
อาจเป็นการยากที่จะพิจารณาว่าการผูกมัดเกิดในช่วงใด ทั้งนี้ต้องวิเคราะห์กันในแต่ละภาษา เพราะแต่ละภาษาการโปรแกรมอาจมีการจัดการที่แตกต่างกันในบางเรื่อง
Binding คือ การผูกมัดสิ่ง 2 สิ่งเข้าด้วยกัน เช่น ไทป์กับตัวแปร โอเปอเรเตอร์กับการดำเนินการ ตัวแปรกับตำแหน่งอ้างอิงในเมมโมรี
Binding เกิดได้ตลอดเวลา อาจพิจารณาเวลาผูกมัดได้หลายเวลา เช่น
1. Language design time
2. Language implementation time
3. Compile time
4. Link time
5. Load time
6. Run time
Language design time
การผูกมัดที่เกิดในช่วงการออกแบบภาษา เช่น การออกแบบชิ้นส่วนต่างๆ (construct) ของภาษา เช่น สัญลักษณ์ตัวดำเนินการแทนการดำเนินการ (+ แทนการบวก, - แทนการลบ เป็นต้น) รูปแบบ Statement (if-else, while, for) ไทป์ต่างๆ
Language implementation time
การผูกมัดที่เกิดในเวลานำไปใช้ เกี่ยวข้องกับการกำหนดรูปแบบของ Precision ของ Floating-point number และ การแสดงในเมมโมรีของ data type ชนิดต่างๆ (ใช่กี่บิต เรียงบิตอย่างไร เลขยกกำลังใช้มาตรฐานอะไร) การจัดการเมมโมรีของโปรแกรม หรือฟงัก์ชั่น การจัดการเมมโมรีของตัวแปร local และ nonlocal การจัดการตรวจจับรันไทม์ error เช่น Overflow
Compile time
การผูกมัดที่เกิดในเวลาคอมไพล์ เช่น การจับคู่ระหว่าง Token กับ Lexeme ในตาราง Symbol table เช่น ตัวแปรกับไทป์ เครื่องหมายดำเนินการกับตัวดำเนินการ หรือการผูกมัดระหว่างตัวดำเนินการกับ Machine code (เช่น + ผูกมัดกับคำสั่ง ADD ของ Machine code รุ่น intel....)
Link time
ในการเขียนโปรแกรมบางครั้งอาจมีการแยกโปรแกรมออกเป็นส่วนๆ แล้วแยกคอมไพล์ ในเวลานี้คือเวลาที่เกิดขึ้นเพื่อนำโค้ดที่ผ่านการคอมไพล์มารวมเข้าด้วยกัน ก่อนที่จะสร้าง Machine code (ซึ่งจะมีเพียงส่วนเดิยวที่สามารถนำไปรันได้) ยกตัวอย่างในภาษา C เราอาจแยกโค้ดเป็นหลายส่วน เมื่อคอมไพล์จะได้ .OBJ แล้วในเวลา Link time คือผููกมัดที่นำ .OBJ มารวมกัน นอกจากนี้แล้วอาจพิจารณาการรวมโค้ดของโปรแกรมเข้ากับโค้ดของ OS เพื่อใช้งาน I/O ได้อีกด้วย
Load time
คือเวลาผูกมัดที่เกิดขึ้นเมื่อ OS โหลดโปรแกรมเข้าไปไว้ในเมมโมรีก่อนรัน ตัวอย่างเช่น การโหลดตัวแปรประเภท Static จะเกิดการผูกมัดไปยัง Physical address ตำแหน่งหนึ่ง ตลอดการรันโปรแกรม
(ดูการใช้งานตัวแปร Static) อะไรก็ตามที่ถูกกำหนดผูกเข้ากับ Physical address เกิดการผูกมัดในเวลา load time เช่น ค่าคงที่ต่างๆเช่นกัน
Runtime
การผูกมัดที่เกิดในเวลารัน เช่น ตัวแปรกับค่าของตัวแปร ตัวแปร (dynamic variable) กับตำแหน่งในเมมโมรี (ซึ่งอาจเปลี่ยนไปได้ตลอดเวลา)
คำสั่งหนึ่งคำสั่งอาจเกี่ยวข้องกับการผูกมัดได้หลายลักษณะ เช่น
int x = 10;
ค่าคงที่ 10 มีการผูกมัดไปยังตำแหน่งในเมมโมรี (อาจอยู่ในรีจิสเตอร์ก็ได้) ในเวลา Load time
ตัวแปร x มีการผูกมัดไปยังไทป์ในเวลาคอมไพล์
ส่วนตัวแปร x จะผูกมัดไปยังตำแหน่งในเมมโมรี (หรือรีจิสเตอร์) ของค่าคงที่ 10 จะรู้ก็ตอนรันไทม์ (ไม่รู้ตอนคอมไพล์เพราะช่วงคอมไพล์ x ยังไม่ผูกมัดไปยัง Physical address แต่อาจผูกไป virtual address ก็ได้ถ้าภาษากำหนดขึ้นมาชั่วคราว)
อาจเป็นการยากที่จะพิจารณาว่าการผูกมัดเกิดในช่วงใด ทั้งนี้ต้องวิเคราะห์กันในแต่ละภาษา เพราะแต่ละภาษาการโปรแกรมอาจมีการจัดการที่แตกต่างกันในบางเรื่อง
Semantics ของโปรแกรม
Semantics ของโปรแกรม
การบรรยาย Syntax ของโปรแกรมมักจะง่ายกว่า Semantics ของโปรแกรม Semantics ของโปรแกรม บ่งบอกความหมายในการทำงานของนิพจน์ ประโยค หรือ โปรแกรม
ในกระบวนการคอมไพล์ในขั้นตอนของ Syntax analysis นั้น เป็นการตรวจสอบความถูกต้องของโปรแกรมตามรูปแบบของภาษาที่กำหนด โดยอาศัย Symbol table ก่อนที่คอมไพเลอร์จะสร้าง Intermediate code จะมีการกระบวนการ Semantic analysis คือ กระบวนการค้นหาความหมายของการทำงานของโปรแกรม เช่น
1. การตรวจสอบว่า Identifier ทุกตัวมีการประกาศไทป์ (สำหรับภาษาการโปรแกรมประเภท Static type binding)
2. การตรวจสอบ Type checking (การนำไทป์ไปใช้กับ Operator มีความถูกต้องหรือไม่)
3. การเรียก subprogram มีการกำหนดพารามิเตอร์ครบถ้วน และไทป์ถูกต้องกับการประกาศฟังก์ชั่น
4. ใน Statement มีการกำหนดค่า Label ที่ถูกต้องเช่น คำสั่ง switch นั้นใน case จะต้องเป็น Integer เท่านั้น
5. ฟังก์ชั่นที่มีการรีเทิร์นค่ากลับต้องมีคำสั่ง return ทุกฟังก์ชั่น
อย่างไรก็ตามการตรวจสอบ error ตาม semantic analysis ก็ยังไม่สามารถตรวจ error ได้ทุกอย่าง ฉะนั้นการตรวจสอบ error บางลักษณะจะมีการตรวจสอบใน runtime (เวลารันโปรแกรม)
เช่น subscript ของอะเรย์ต้องไม่อ้างอิงเกินขนาดของอะเรย์ (error: Array index out of bound) พอยน์เตอร์ไม่เคยถูกใช้งานในการอ้างอิงถึงแม้มีการกำหนดพอยน์เตอร์ หรือตัวแปรไม่เคยถูกใช้งาน และการประมวลผลจะต้องไม่เกิด Overflow
มีวิธีการหลายอย่างในการกำหนด Semantics ของภาษา เช่น สร้าง Attribute Grammar, Operational semantics, Denotational semantics, และ Axiomatic Semantics
ในที่นี้ขอยกตัวอย่าง Attribute Grammar ซึ่งอาจกำหนดควบคู่กระบวนการสร้าง CFG Grammar
เช่น
1. Syntax rule: <assign>→ <var> = <expr>
Semantic rule: <expr>.expected_type ← <var>.actual_type
แสดงความหมายการนำไทป์ของตัวแปร ให้กับ ไทป์ผลลัพธ์จากการประเมินผลนิพจน์
2. Syntax rule: <expr>→ <var> [2] + <var> [3]
Semantic rule: <expr>.actual_type ←
if (<var>[2].actual_type = int) and
(<var>[3].actual_type = int)
then int
else real
end if
Predicate: <expr>.actual_type == <expr>.expected_type
3. Syntax rule: <expr>→ <var>
Semantic rule: <expr>.actual_type ← <var>.actual_type
Predicate: <expr>.actual_type == <expr>.expected_type
4. Syntax rule: <var> → A | B | C
Semantic rule: <var>.actual_type ← look-up(<var>.string)
actual type ค่าไทป์ที่เกี่ยวข้องกับ nonterminal <var> และ <expr>
expected type ค่าไทป์ที่คาดว่า expression จะได้ หรือไทป์นี้เกี่ยวข้องกับ <expr>
จาก Attribute grammar จะแสดง Parse tree ได้ดังภาพ 3.6 ซึ่งกฎข้อ 1 - 4 จะนำเข้าใช้ตรวจสอบ Type checking
อีกวิธีการหนึ่งที่น่าสนใจคือ Axiomatic Semantics ศึกษาต่อในแบบฝึกหัด
การบรรยาย Syntax ของโปรแกรมมักจะง่ายกว่า Semantics ของโปรแกรม Semantics ของโปรแกรม บ่งบอกความหมายในการทำงานของนิพจน์ ประโยค หรือ โปรแกรม
ในกระบวนการคอมไพล์ในขั้นตอนของ Syntax analysis นั้น เป็นการตรวจสอบความถูกต้องของโปรแกรมตามรูปแบบของภาษาที่กำหนด โดยอาศัย Symbol table ก่อนที่คอมไพเลอร์จะสร้าง Intermediate code จะมีการกระบวนการ Semantic analysis คือ กระบวนการค้นหาความหมายของการทำงานของโปรแกรม เช่น
1. การตรวจสอบว่า Identifier ทุกตัวมีการประกาศไทป์ (สำหรับภาษาการโปรแกรมประเภท Static type binding)
2. การตรวจสอบ Type checking (การนำไทป์ไปใช้กับ Operator มีความถูกต้องหรือไม่)
3. การเรียก subprogram มีการกำหนดพารามิเตอร์ครบถ้วน และไทป์ถูกต้องกับการประกาศฟังก์ชั่น
4. ใน Statement มีการกำหนดค่า Label ที่ถูกต้องเช่น คำสั่ง switch นั้นใน case จะต้องเป็น Integer เท่านั้น
5. ฟังก์ชั่นที่มีการรีเทิร์นค่ากลับต้องมีคำสั่ง return ทุกฟังก์ชั่น
อย่างไรก็ตามการตรวจสอบ error ตาม semantic analysis ก็ยังไม่สามารถตรวจ error ได้ทุกอย่าง ฉะนั้นการตรวจสอบ error บางลักษณะจะมีการตรวจสอบใน runtime (เวลารันโปรแกรม)
เช่น subscript ของอะเรย์ต้องไม่อ้างอิงเกินขนาดของอะเรย์ (error: Array index out of bound) พอยน์เตอร์ไม่เคยถูกใช้งานในการอ้างอิงถึงแม้มีการกำหนดพอยน์เตอร์ หรือตัวแปรไม่เคยถูกใช้งาน และการประมวลผลจะต้องไม่เกิด Overflow
มีวิธีการหลายอย่างในการกำหนด Semantics ของภาษา เช่น สร้าง Attribute Grammar, Operational semantics, Denotational semantics, และ Axiomatic Semantics
ในที่นี้ขอยกตัวอย่าง Attribute Grammar ซึ่งอาจกำหนดควบคู่กระบวนการสร้าง CFG Grammar
เช่น
1. Syntax rule: <assign>
แสดงความหมายการนำไทป์ของตัวแปร ให้กับ ไทป์ผลลัพธ์จากการประเมินผลนิพจน์
2. Syntax rule: <expr>
actual type ค่าไทป์ที่เกี่ยวข้องกับ nonterminal <var> และ <expr>
expected type ค่าไทป์ที่คาดว่า expression จะได้ หรือไทป์นี้เกี่ยวข้องกับ <expr>
จาก Attribute grammar จะแสดง Parse tree ได้ดังภาพ 3.6 ซึ่งกฎข้อ 1 - 4 จะนำเข้าใช้ตรวจสอบ Type checking
อีกวิธีการหนึ่งที่น่าสนใจคือ Axiomatic Semantics ศึกษาต่อในแบบฝึกหัด
ปัญหา Side effect
ปัญหา Side effect และ Referential Transparency
ในการเขียนโปรแกรมที่เกี่ยวข้องกับนิพจน์ ในบางครั้งก็อาจเกิดปัญหา Side effect (ผลกระทบซึ่งเราไม่ทราบ) ปัญหานี้จะทำให้โปรแกรมเมอร์ debug โปรแกรมไม่ได้ หากไม่เข้าใจถึงผลกระทบที่เกิดขึ้น ปัญหานี้มักเกี่ยวข้องกับเรียกใช้งานฟังก์ชั่นในโปรแกรมซึ่งเราเรียกว่าเกิด Functional side effect
นิพจน์ (expression)
result = A * B + myfunction( ) + 20;
คำถามคือ
1. เมื่อนิพจน์ (expression) มีการเรียกใช้ฟังก์ชั่น โปรแกรมเมอร์ทราบหรือไม่ว่าภาษาการโปรแกรมนั้นการประเมินผลนิพจน์จะยังคงพิจารณาตาม Precedence rule และ Associativity หรือจะต้องพิจารณาการเรียกฟังก์ชั่นร่วมด้วย เช่น ต้องเรียกก่อนค่อยประเมินนิพจน์ตาม Precedence rule และ Associativity
คำตอบ ถ้าไม่ทราบต้องไปดู Specification ของภาษา แต่ละภาษาอาจไม่เหมือนกัน ส่วนใหญ่ภาษามักกำหนดให้เรียกฟังก์ชั่นให้เสร็จก่อน แล้วค่อยประเมินนิพจน์
2. ถ้าการเรียกฟังก์ชั่นมีการแก้ไขค่าของตัวแปรที่ปรากฎในนิพจน์ เช่น ตัวแปร A หรือ B (สมมติ A หรือ B เป็น Nonlocal variable ที่ฟังก์ชั่นสามารถเข้าถึงได้ ดังนั้นลำดับการเรียกฟังก์ชั่นก่อนและหลังจะมีผลต่อผลลัพธ์หรือไม่ ?
คำตอบ มีแน่นอน สมมติว่าเรียกฟังก์ชั่นก่อน ดังนั้นค่า A และ B ที่อาจเกิดการแก้ไขจะเป็นค่าหลังจากเรียกฟังก์ชั่น ถ้าเรียกฟังก์ชั่นภายหลัง (ทำตาม Precedence rule และ Associativity ตามปกติ) ค่า A และ B ในนิพจน์จะเป็นค่าก่อนเรียกฟังก์ชั่น และต้องจำไว้ว่าในบรรทัดถัดไปจะใช้ค่า A และ B จะเป็นค่าใหม่ที่ถูกแก้ไขแล้ว
สาเหตุจาก Functional Side Effect จึงมาจาก 2 กรณี
1. การเรียกฟังก์ชั่นในนิพจน์ที่มีการแก้ไขค่าของตัวแปร Nonlocal variable ในนิพจน์
#include <stdio.h>
int A = 20, B=5;
void main( ){
result = A * B + myfunction( ) + 20;
...
}
int myfunction( ){
A = A +10 ;
....
return A;
}
2. การเรียกฟังก์ชั่นที่พารามิเตอร์ทำงานแบบ out mode หรือ inout mode ซึ่งค่าถูกส่งกลับไปยังเออร์กูเมนต์ที่ปรากฎในนิพจน์ เช่น
void main( ){
int A = 20, B = 5;
result = A * B + myfunction (&A) + 20;
}
void myfunction(int *p){
*p = *p + 10;
}
ความเข้าใจจะเหมือนกรณีแรก
วิธีแก้ไข
พยายามหลีกเลี่ยงการเขียนโค้ดในลักษณะนี้ หากไม่แน่ใจว่าภาษาการโปรแกรมจะมีลำดับการประเมินผลอย่างไร เมื่อมีการเรียกฟังก์ชั่นในนิพจน์ ?
อาจจัดเรียงนิพจน์ใหม่ เช่น
result = A * B + 20;
result = result + myfunction( );
หรือ
result = result =+ myfunction(&A);
ซึ่งเมื่อเรียงใหม่ค่า A ที่นำไปคูณกับ B จะมีค่าเท่ากับ 20 ตามความเข้าใจแรกเริ่ม
Referential transparency
สมมติ
result1 = (myfunction (A) + B) / (myfunction (A) - C);
temp = myfunction(A);
result2 = (temp + B) / (temp - C);
ถ้าการเรียกฟังก์ชั่นไม่มีการแก้ไขค่าตัวแปรใดๆ (A , B, C) ที่เกี่ยวข้องกับนิพจน์ คำสั่งบรรทัดแรกและบรรทัดที่สาม น่าจะได้ผลลัพธ์เดียวกัน เนื่องจากไม่เกิด Functional side effect
เราจะเรียกว่าโปรแกรมมีคุณสมบัติ Referential transparency
แต่ถ้าเกิดเรียกฟังก์ชั่นในบรรทัดแรกมีการแก้ไขค่า A, B หรือ C จากการเรียกฟังก์ชั่นแล้ว ผลลัพธ์จากคำสั่งในบรรทัดแรก และบรรทัดสุดท้ายจะไม่เท่ากันทันที
ในการเขียนโปรแกรมที่เกี่ยวข้องกับนิพจน์ ในบางครั้งก็อาจเกิดปัญหา Side effect (ผลกระทบซึ่งเราไม่ทราบ) ปัญหานี้จะทำให้โปรแกรมเมอร์ debug โปรแกรมไม่ได้ หากไม่เข้าใจถึงผลกระทบที่เกิดขึ้น ปัญหานี้มักเกี่ยวข้องกับเรียกใช้งานฟังก์ชั่นในโปรแกรมซึ่งเราเรียกว่าเกิด Functional side effect
นิพจน์ (expression)
result = A * B + myfunction( ) + 20;
1. เมื่อนิพจน์ (expression) มีการเรียกใช้ฟังก์ชั่น โปรแกรมเมอร์ทราบหรือไม่ว่าภาษาการโปรแกรมนั้นการประเมินผลนิพจน์จะยังคงพิจารณาตาม Precedence rule และ Associativity หรือจะต้องพิจารณาการเรียกฟังก์ชั่นร่วมด้วย เช่น ต้องเรียกก่อนค่อยประเมินนิพจน์ตาม Precedence rule และ Associativity
คำตอบ ถ้าไม่ทราบต้องไปดู Specification ของภาษา แต่ละภาษาอาจไม่เหมือนกัน ส่วนใหญ่ภาษามักกำหนดให้เรียกฟังก์ชั่นให้เสร็จก่อน แล้วค่อยประเมินนิพจน์
2. ถ้าการเรียกฟังก์ชั่นมีการแก้ไขค่าของตัวแปรที่ปรากฎในนิพจน์ เช่น ตัวแปร A หรือ B (สมมติ A หรือ B เป็น Nonlocal variable ที่ฟังก์ชั่นสามารถเข้าถึงได้ ดังนั้นลำดับการเรียกฟังก์ชั่นก่อนและหลังจะมีผลต่อผลลัพธ์หรือไม่ ?
คำตอบ มีแน่นอน สมมติว่าเรียกฟังก์ชั่นก่อน ดังนั้นค่า A และ B ที่อาจเกิดการแก้ไขจะเป็นค่าหลังจากเรียกฟังก์ชั่น ถ้าเรียกฟังก์ชั่นภายหลัง (ทำตาม Precedence rule และ Associativity ตามปกติ) ค่า A และ B ในนิพจน์จะเป็นค่าก่อนเรียกฟังก์ชั่น และต้องจำไว้ว่าในบรรทัดถัดไปจะใช้ค่า A และ B จะเป็นค่าใหม่ที่ถูกแก้ไขแล้ว
สาเหตุจาก Functional Side Effect จึงมาจาก 2 กรณี
1. การเรียกฟังก์ชั่นในนิพจน์ที่มีการแก้ไขค่าของตัวแปร Nonlocal variable ในนิพจน์
#include <stdio.h>
int A = 20, B=5;
void main( ){
result = A * B + myfunction( ) + 20;
...
}
int myfunction( ){
A = A +10 ;
....
return A;
}
เมื่อโปรแกรมเมอร์ทั่วไปที่ไม่ทราบปัญหา Functional side effect จะเข้าใจว่าตัวแปร result จะมีค่าเป็น 150
result (150) = 20 * 5 + 30 + 20
แต่ความจริงแล้วเป็น 200
result (200) = 30 * 5 + 30 + 20
void main( ){
int A = 20, B = 5;
result = A * B + myfunction (&A) + 20;
}
void myfunction(int *p){
*p = *p + 10;
}
ความเข้าใจจะเหมือนกรณีแรก
วิธีแก้ไข
พยายามหลีกเลี่ยงการเขียนโค้ดในลักษณะนี้ หากไม่แน่ใจว่าภาษาการโปรแกรมจะมีลำดับการประเมินผลอย่างไร เมื่อมีการเรียกฟังก์ชั่นในนิพจน์ ?
อาจจัดเรียงนิพจน์ใหม่ เช่น
result = A * B + 20;
result = result + myfunction( );
หรือ
result = result =+ myfunction(&A);
ซึ่งเมื่อเรียงใหม่ค่า A ที่นำไปคูณกับ B จะมีค่าเท่ากับ 20 ตามความเข้าใจแรกเริ่ม
Referential transparency
สมมติ
result1 = (myfunction (A) + B) / (myfunction (A) - C);
temp = myfunction(A);
result2 = (temp + B) / (temp - C);
ถ้าการเรียกฟังก์ชั่นไม่มีการแก้ไขค่าตัวแปรใดๆ (A , B, C) ที่เกี่ยวข้องกับนิพจน์ คำสั่งบรรทัดแรกและบรรทัดที่สาม น่าจะได้ผลลัพธ์เดียวกัน เนื่องจากไม่เกิด Functional side effect
เราจะเรียกว่าโปรแกรมมีคุณสมบัติ Referential transparency
แต่ถ้าเกิดเรียกฟังก์ชั่นในบรรทัดแรกมีการแก้ไขค่า A, B หรือ C จากการเรียกฟังก์ชั่นแล้ว ผลลัพธ์จากคำสั่งในบรรทัดแรก และบรรทัดสุดท้ายจะไม่เท่ากันทันที
Friday, July 17, 2015
พอยน์เตอร์ คืออะไร ?
พอยน์เตอร์ (Pointer) คือตัวชี้ไปยังตำแหน่งในเมมโมรี พูดถึงตัวชี้ (หนังสือบางเล่มใช้คำว่า ดัชนี) คงจะนึกภาพไม่ออกว่าคืออะไรในคอมพิวเตอร์ พอยน์เตอร์คือรีจิสเตอร์ (register) ตัวหนึ่งซึ่งถูกใช้เพื่ออ้างอิงตำแหน่งในเมมโมรี ในคอมพิวเตอร์มีรีจิสเตอร์จำนวนมากมาย เวลาที่โปรแกรมทำงานทุกๆอย่างในโปรแกรมเช่น คำสั่ง ตัวแปร ค่าของตัวแปร ค่าคงที่ของโปรแกรมจะถูกโหลดเข้าไปไว้ในเมมโมรี ทั้งนี้เนื่องจากสถาปัตยกรรมคอมพิวเตอร์ในปัจจุบันส่วนใหญ่ทำงานตามสถาปัตยกรรม von Neumann (เจ้าของชื่อเต็มๆว่า John von Neumann) ซึ่งคอมพิวเตอร์มีองค์ประกอบหลัก 4 ส่วน คือ Input, Output, Processor (มี ALU และ Control Unit เป็นองค์ประกอบ) และ Memory ในระหว่างที่คอมพิวเตอร์ทำการประมวลผลจะมีการเรียกใช้งานรีจิสเตอร์ตลอดเวลา

จากภาพด้านบน พอยน์เตอร์เก็บตำแหน่งในเมมโมรีคือ #100 ข้อมูลที่เก็บในตำแหน่งนั้นอาจเป็นค่าข้อมูล หรือค่าตำแหน่งก็ได้ ขึ้นกับว่าคำสั่งที่เกี่ยวข้องกับการใช้งาน Pointer นั้นมี Addressing Mode อย่างไร (ศึกษาต่อเรื่อง Memory Addressing Mode)
การใช้งานพอยน์เตอร์ในภาษาการโปรแกรมต่างๆ เกี่ยวข้องกับการกำหนดค่าโดยเอาตำแหน่งในเมมโมรีของตัวแปรหนึ่งให้อีกตัวแปรหนึ่ง ซึ่งสิ่งที่จะตามมาคือ หากการใช้งานตัวแปรทั้งสองอยู่ในขอบเขต (scope) การทำงานเดียวกัน ดังนั้นจะเกิดปัญหา Aliasing คือ การอ้างอิงไปยังตำแหน่งในเมมโมรีหนึ่งๆ ซึ่งสามารถทำได้โดยผ่านตัวแปรมากกว่า 1 ตัวแปร ผลที่ต้องระวังตามมาคือ หากมีการแก้ไขค่าผ่านตัวแปรตัวใดตัวหนึ่ง ตัวแปรทั้งสองนั้นจะมีค่าเดียวกันทันที (โปรแกรมเมอร์ต้องจำเพิ่มว่าโดนแก้ในตำแหน่งไหนในโปรแกรม ไล่กันยาวถ้าใช้ตัวแปรทั้งสองตัวโดยไม่ระวัง) เช่น ในภาษา C
1
2
3
4
5
6
7
8
9
10
11
|
#include <stdio.h>
void main()
{
int *p;
int q;
q =10;
p = &q;
printf("p = %d, q = %d",*p, q);
*p = 20;
printf("p = %d, q = %d",*p, q);
}
|
สมมติว่าโค้ดดังกล่าวอยู่ในฟังก์ชั่น main( ) เราจะถือว่าคำสั่งทั้งหลายนั้นทำงานภายในขอบเขตเดียวกัน ซึ่งก็คือฟังก์ชั่น main นั่นเอง
ในบรรทัดที่ 7 พอยน์เตอร์ p จะเก็บตำแหน่งที่อยู่ของตัวแปร q สมมติอยู่ที่ตำแหน่งที่ 100

ในบรรทัดที่ 8 ค่าของ p และ q ที่แสดงผลจะมีค่าเท่ากับ 10
ในบรรทัดที่ 9 การกำหนด *p หมายถึงการแก้ไขค่าข้อมูลที่พอยน์เตอร์ p ชี้อยู่ ซึ่งค่าข้อมูลจะถูกแก้ไขเป็น 20 ดังนั้นบรรทัดที่ 10 จะแสดงค่าของ p และ q ซึ่งเท่ากับ 20

ข้อดีในการใช้งานพอยน์เตอร์คืออะไร ?
จากโค้ดที่ผ่านมาถ้าพอยน์เตอร์ถูกใช้งานภายในฟังก์ชั่นเดียวกันจะเกิดปัญหา Aliasing แล้วทำไมเราเลือกใช้พอยน์เตอร์ คำตอบคือมันดีสำหรับการสำเนาข้อมูลในเมมโมรีขนาดใหญ่ ไปไว้ในพื้นที่ที่ต้องการประมวลผลข้อมูลเป็นพิเศษเพียงชั่วคราว จะขอยกตัวอย่างการใช้งานพอยน์เตอร์ในฟังก์ชั่น เมื่อมีการส่งผ่านค่าเออร์กูเมนต์ (Argument: ตัวแปรที่เป็นอินพุตที่ถูกส่งให้ฟังก์ชั่น ) ให้กับพารามิเตอร์ (Parameter: ตัวแปรที่รับค่าภายในฟังก์ชั่น) ในฟังก์ชั่น
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#include <stdio.h>
void main()
{
int q, returnresult;
q =10;
printf("q = %d ", q);
myfunction(&q);
printf("q = %d ", q);
}
void myfunction(int *p){
printf("p = %d ",*p);
*p = 20;
printf("p = %d", *p);
}
|
จากโค้ดข้างต้น p และ q ถือว่าทำงานภายในขอบเขตที่แตกต่างกัน จะไม่เกิดปัญหา Aliasing ตัวแปร q ทำงานในฟังก์ชั่น main ขณะที่ตัวแปร p ทำงานภายในฟังก์ชั่น การส่งค่าคือตำแหน่งในเมมโมรีของ q คือ การทำสำเนาค่าข้อมูลในตำแหน่งนั้นให้กับตัวแปรของฟังก์ชั่น เมื่อโปรแกรมรันมาถึงบรรทัดที่ 7 จะเกิดการจองพื้นที่ (memory allocation) ในเมมโมรีสำหรับเก็บตัวแปร ค่าของตัวแปร และคำสั่งของฟังก์ชั่น แต่พื้นที่นี้จะอยู่ชั่วขณะจนกระทั่งออกจากฟังก์ชั่น (กลับไปทำงานต่อที่บรรทัดที่ 9 ) พื้นที่จะหายไป แต่ค่าที่ถูกแก้ไขจะถูกสำเนากลับให้กับตัวแปรเออร์กูเมนต์ต้นทาง ดังนั้นการใช้งานพอยน์เตอร์ p ในฟังก์ชั่น จะเป็นการทำสำเนาค่าของตัวแปร q มาไว้ในพื้นที่ส่วนของฟังก์ชั่นและค่าข้อมูลที่ถูกปรับปรุงจะถูกสำเนากลับไปยังเออร์กูเมนต์ต้นทาง
ถ้าเรานึกถึงการส่งตัวแปรพารามิเตอร์ที่เป็นชนิด struct นั่นก็หมายถึงการสำเนาข้อมูลที่มีโครงสร้าง (ซึ่งมักจะมีข้อมูลมากๆ) และในกรณีนี้เรานำข้อมูลใหญ่ๆนั้นมาประมวลผล โดยที่ต้นฉบับ (เออร์กูเมนต์) ที่ส่งมาถูกแก้ไขด้วยพารามิเตอร์ภายในฟังก์ชั่น
การใช้งานพอยน์เตอร์จึงมีประโยชน์แทนการส่งเออร์กูเมนต์หลายๆตัวเข้าสู่ฟังก์ชั่นและการใช้งานเสมือนการรีเทิร์นค่ากลับไปยังเออร์กูเมนต์ (การใช้พารามิเตอร์ของฟังก์ชั่นทำงานในโหมด in-out parameter mode)
จากโค้ดตัวอย่างพอยน์เตอร์ p ในฟังก์ชั่นถูกแก้ไขให้มีค่าเป็น 20 และค่านั้นจะถูกสำเนากลับไปยังตำแหน่งของตัวแปร q ให้เป็น 20 ก่อนที่จะออกจากฟังก์ชั่น
สรุป สิ่งที่เราจะต้องเข้าใจ
- ถ้าใช้พอยน์เตอร์ภายใน Scope เดียวกันกับตัวแปรที่ถูกอ้างอิงจะเกิด Aliasing การเข้าถึงเมมโมรีในตำแหน่งหนึ่งๆ ที่สามารถเข้าถึงได้จากตัวแปรมากกว่า 1 ตัวแปร
- ถ้าใช้พอยน์เตอร์เพื่อรับค่าที่ส่งมาในฟังก์ชั่น เป็นการสำเนาค่าข้อมูลในตำแหน่งที่พารามิเตอร์ชี้อยู่ ไม่เกิด Aliasing แต่มีการสำเนาค่าที่ถูกปรับปรุงกลับไปก่อนออกจากการทำงานของฟังก์ชั่น

Precedence rule และ Associativity
Precedence rule และ Associativity
Precedence rule คือกฎที่กำหนดความสำคัญของตัวดำเนินการ (operators) ซึ่งในการประเมินผลนิพจน์จะประเมินผลนิพจน์ตามความสำคัญของตัวดำเนินการ อะไรสำคัญก่อนก็จะถูกดำเนินการก่อน และอะไรสำคัญน้อยจะถูกดำเนินการเป็นลำดับถัดไป
Associativity คือการพิจารณาว่าในกรณีที่ตัวดำเนินการมีความสำคัญเท่ากันนั้น จะประเมินผลอย่างไร เช่น ประเมินตามลำดับของตัวดำเนินการจากซ้ายมือไปขวามือหรือจากขวามือไปซ้ายมือ ภาษาแต่ละภาษามีการออกแบบที่แตกต่างกันได้ ภาษาส่วนใหญ่เลือกกำหนดการดำเนินการจากซ้ายมือไปขวามือ
เช่น
A = B + C * 10 / 40
ถ้าความสำคัญของตัวดำเนินการจากสำคัญมากไปสำคัญน้อยคือ
* /,
+
=
และ Associativity กำหนดให้ดำเนินการจากซ้ายไปขวา
การประเมินผลนิพจน์คือ
C * 10 -> ผลลัพธ์1
ผลลัพธ์1 / 40 -> ผลลัพธ์2
B + ผลลัพธ์2 -> ผลลัพธ์3
ผลลัพธ์3 -> A
Precedence rule คือกฎที่กำหนดความสำคัญของตัวดำเนินการ (operators) ซึ่งในการประเมินผลนิพจน์จะประเมินผลนิพจน์ตามความสำคัญของตัวดำเนินการ อะไรสำคัญก่อนก็จะถูกดำเนินการก่อน และอะไรสำคัญน้อยจะถูกดำเนินการเป็นลำดับถัดไป
Associativity คือการพิจารณาว่าในกรณีที่ตัวดำเนินการมีความสำคัญเท่ากันนั้น จะประเมินผลอย่างไร เช่น ประเมินตามลำดับของตัวดำเนินการจากซ้ายมือไปขวามือหรือจากขวามือไปซ้ายมือ ภาษาแต่ละภาษามีการออกแบบที่แตกต่างกันได้ ภาษาส่วนใหญ่เลือกกำหนดการดำเนินการจากซ้ายมือไปขวามือ
เช่น
A = B + C * 10 / 40
ถ้าความสำคัญของตัวดำเนินการจากสำคัญมากไปสำคัญน้อยคือ
* /,
+
=
และ Associativity กำหนดให้ดำเนินการจากซ้ายไปขวา
การประเมินผลนิพจน์คือ
C * 10 -> ผลลัพธ์1
ผลลัพธ์1 / 40 -> ผลลัพธ์2
B + ผลลัพธ์2 -> ผลลัพธ์3
ผลลัพธ์3 -> A
หรือ
(A = (B + ((C * 10)1 /40 )2) 3) 4
[ทำแบบฝึกหัด]
Parse Tree และ Ambiguous Grammar
Parse Tree และ Ambiguous Grammar
ในเรื่อง Syntax analysis จะเห็นได้ว่า Parse Tree ถูกนำมาใช้ในการวิเคราะห์รูปแบบ (syntax) ของภาษาตามไวยากรณ์หนึ่งๆ ที่กำหนดขึ้น และจะเห็นได้ว่า Parse tree สามารถใช้ตรวจสอบ syntax error (error จากการเขียนประโยคที่ไม่เป็นไปตาม Grammar ของภาษา) ได้
นอกจากนี้แล้ว Compiler ยังใช้ประโยชน์ในการตรวจสอบความกำกวมของการออกแบบไวยากรณ์ของภาษาอีกด้วย กล่าวคือในการออกแบบภาษาการโปรแกรมหนึ่งๆนั้นอาจเป็นไปได้ว่าผู้ออกแบบมีการกำหนดไวยากรณ์ที่กำกวมทำให้เกิดความหมายของการประเมินผลที่มากกว่า 1 รูปแบบได้
ขอยกตัวอย่างเช่น หากภาษา Anonymous (ภาษาสมมติขึ้นมา) กำหนดว่าเครื่องหมาย + (บวก) และ * (คูณ) มีลำดับความสำคัญจากต่ำไปสูงตามลำดับ แต่ Compiler สามารถพิจารณาลำดับการประเมินผลนิพจน์จาก Parse tree พบว่าสื่อความหมาย 2 แบบ แบบแรกคือประเมินผลนิพจน์ + ก่อน * และอีก Parse tree แสดงการประเมินนิพจน์ * ก่อน +
สมมติกำหนด Grammar คือ
<assign> → <id> = <expr>
<id> → A | B | C
<expr> → <expr> + <expr>
| <expr> * <expr>
| ( <expr> )
| <id>
A = B + C * A สามารถแสดงได้ด้วย Parse tree คือ

ในเรื่อง Syntax analysis จะเห็นได้ว่า Parse Tree ถูกนำมาใช้ในการวิเคราะห์รูปแบบ (syntax) ของภาษาตามไวยากรณ์หนึ่งๆ ที่กำหนดขึ้น และจะเห็นได้ว่า Parse tree สามารถใช้ตรวจสอบ syntax error (error จากการเขียนประโยคที่ไม่เป็นไปตาม Grammar ของภาษา) ได้
นอกจากนี้แล้ว Compiler ยังใช้ประโยชน์ในการตรวจสอบความกำกวมของการออกแบบไวยากรณ์ของภาษาอีกด้วย กล่าวคือในการออกแบบภาษาการโปรแกรมหนึ่งๆนั้นอาจเป็นไปได้ว่าผู้ออกแบบมีการกำหนดไวยากรณ์ที่กำกวมทำให้เกิดความหมายของการประเมินผลที่มากกว่า 1 รูปแบบได้
ขอยกตัวอย่างเช่น หากภาษา Anonymous (ภาษาสมมติขึ้นมา) กำหนดว่าเครื่องหมาย + (บวก) และ * (คูณ) มีลำดับความสำคัญจากต่ำไปสูงตามลำดับ แต่ Compiler สามารถพิจารณาลำดับการประเมินผลนิพจน์จาก Parse tree พบว่าสื่อความหมาย 2 แบบ แบบแรกคือประเมินผลนิพจน์ + ก่อน * และอีก Parse tree แสดงการประเมินนิพจน์ * ก่อน +
สมมติกำหนด Grammar คือ
<assign> → <id> = <expr>
<id> → A | B | C
<expr> → <expr> + <expr>
| <expr> * <expr>
| ( <expr> )
| <id>
A = B + C * A สามารถแสดงได้ด้วย Parse tree คือ

การท่องต้นไม้แบบ Preorder จากต้นไม้ด้านซ้ายและขวาจะได้
A = B + (C * A)
A = (B + C) * A
ซึ่งแต่ละนิพจน์จะส่งผลลัพธ์ที่มีค่าไม่เท่ากัน ดังนั้นไวยากรณ์นี้จึงมีความกำกวม ซึ่งจะต้องมีการแก้ไขต่อไป ไวยากรณ์ควรจะเป็น
<assign> → <id> = <expr>
<id> → A | B | C
<expr> → <expr> + <term> | <term>
<term> → <term> * <factor> | <factor>
<factor> → ( <expr> ) | <id>
ซึ่งเมื่อสร้าง Parse tree แล้วจะได้เพียงรูปแบบเดียว ซึ่งมีการประเมินผลนิพจน์ด้วย * ก่อน +
ตัวอย่างไวยากรณ์ที่มีความกำกวม
<if_stmt> → if <logic_expr> then <stmt> | if <logic_expr> then <stmt> else <stmt>
<stmt> → <if_stmt>
[ทำในแบบฝึกหัด]
จาก Parse tree เราจะเห็นได้ว่า Parse tree แสดงความสำคัญของเครื่องหมายดำเนินการ (operator) หรือที่เรียกว่า Precedence rule นอกจากนี้แล้ว Parse tree ยังแสดง Associativity อีกด้วย (อ่านต่อใน Blog)
Lexical analysis และ Syntax analysis
Lexical analysis และ Syntax analysis
ในภาษาการโปรแกรม จะมีขั้นตอนของการทำ Lexical analysis และ Syntax analysis ไม่ว่าจะเป็นภาษาที่มีการนำไปใช้แบบ Compilation, Interpretation และแบบผสม ขอยกตัวอย่างในกระบวนการต่างๆของ Compilation แสดงดังภาพ [1]
 กระบวนการที่เกี่ยวข้องกันในการตรวจสอบความถูกต้องของรูปแบบของโปรแกรมคือ
กระบวนการที่เกี่ยวข้องกันในการตรวจสอบความถูกต้องของรูปแบบของโปรแกรมคือ
1. การสร้าง Symbol table
2. Lexical analysis
3. Syntax analysis
Symbol table เก็บข้อมูลได้แก่ Lexemes และ Token ซึ่ง Lexemes คือหน่วยเล็กที่สุดของภาษา และ Token คือข้อมูลรายละเอียดของ Lexemes
result = 3 * number + 10;
Lexemes Tokens
result identifier
= equal_sign
number identifier
10 int_literal
* mult_op
+ plus_op
; semicolon
Lexical analysis เกี่ยวข้องกับการวิเคราะห์รูปแบบนิพจน์ Lexical analyzer คือ Pattern matcher หรือตัวแมชรูปแบบ ที่พยายามหา Substring ของสตริงซึ่งแมชกับรูปแบบสตริงที่กำหนด เช่น นิพจน์ result = 3 * number + 10; จะถูกนำไปวิเคราะห์ด้วย Lexical analysis เพื่อดูว่าภาษาสามารถสร้าง Substring ซึ่งแมชได้กับประโยคหรือไม่ ปกติแล้ว Lexical analyzer จะไม่สนใจ comment และ white space ต่างๆในโปรแกรม error ที่ตรวจพบในการวิเคราะห์ เช่น การกำหนดค่าคงที่ของ Floating point ที่ผิดรูปแบบของภาษา รูปแบบนิพจน์ เครื่องหมายต่างๆ ชื่อตัวแปร และค่าคงที่ ซึ่งจะต้องอาศัยตาราง Symbol table ช่วยในการวิเคราะห์
แนวทางในการพัฒนา Lexical analyzer ที่นิยมเช่น
1. การสร้าง Formal description ด้วยภาษาประเภท Descriptive language แล้วใช้เป็นเครื่องมือในการสร้าง Lexical analyzer
2. การออกแบบ State transition diagram แล้วทำการพัฒนาโปรแกรมตาม State transition diagram ที่ออกแบบ ซึ่งนิยมใช้ finite automata (P.193)
Syntax analysis เป็นการวิเคราะห์รูปแบบของภาษา ซึ่งกระบวนการที่เกี่ยวข้องเรียกว่า Parsing โดย Parser สามารถจำแนกได้ 2 ลักษณะตามทิศทางในการทำงานคือ top-down parser และ bottom-up parser
Top-down Parser สร้าง Parse tree ในลักษณะ preorder การ parse มีลักษณะซ้ายไปขวา โดยเยี่ยมโหนดทุกโหนดจาก root ไปยัง leaf ก่อนที่จะไปโหนดข้างเคียง (โหนดเพื่อนบ้าน)
กำหนด Production rules ต่อไปนี้
A → bB
A → cBb
A → a
พิจารณาประโยค xAz
Parser ต้องเลือกกฎที่น่าจะสร้างประโยคได้ โดยพิจารณาประโยคด้านซ้าย (LHS) ของ Production rule เป็นหลัก ในที่นี้อาจจะตัดสินใจเลือก A → a ซึ่งจะได้ xaz ซึ่งยังไม่แมชกับประโยค xAz อย่างไรก็ตาม Parser จะต้องเลือกใช้กฎอื่นๆจนครบหรือจนกว่าจะหาได้ ในตัวอย่างนี้ xbBz, xcBbz และ xaz เป็นผลลัพธ์จากการ parse ซึ่งไม่สามารถสร้างประโยคที่ต้องการได้เลย
Bottom-up Parser ทำการสร้าง Parse tree โดยดูอักขระในประโยคที่อยู่ด้านขวา (RHS) ของ Production rule แล้วแทนที่ด้วย LHS
S → aAc
A → aA | b
พิจารณาประโยค aabc
เมื่อดูที่ nonterminal symbol นั้น b มี nonterminal symbol ที่เกี่ยวข้องเพียงกฎเดียวดังนั้นจึงแทน LHS ของกฎในประโยค ได้ aaAc ขั้นตอนถัดไปดู RHS ที่แมชกับประโยคล่าสุดได้ aAc ต่อด้วย S ซึ่งเป็น Start symbol หรือท้ายที่สุดจะได้ Derivation สอดคล้องกับ
S => aAc => aaAc => aabc
ไวยากรณ์
<program> → begin <stmt_list> end
<stmt_list> → <stmt> | <stmt> ; <stmt_list>
<stmt> → <var> = <expression>
<var> → A | B | C
<expression> → <var> + <var> | <var> – <var> | <var>
ต้องการวิเคราะห์ว่า ประโยค begin A=B+C ; B = C end เป็นส่วนหนึ่งของภาษาหรือไม่
แสดงได้ด้วย Parse tree ดังนี้

อ้างอิง
[1] Robert W. Sebesta, "Concepts of Programming Languages", Pearson, 10th edition, 2013.
ในภาษาการโปรแกรม จะมีขั้นตอนของการทำ Lexical analysis และ Syntax analysis ไม่ว่าจะเป็นภาษาที่มีการนำไปใช้แบบ Compilation, Interpretation และแบบผสม ขอยกตัวอย่างในกระบวนการต่างๆของ Compilation แสดงดังภาพ [1]

1. การสร้าง Symbol table
2. Lexical analysis
3. Syntax analysis
Symbol table เก็บข้อมูลได้แก่ Lexemes และ Token ซึ่ง Lexemes คือหน่วยเล็กที่สุดของภาษา และ Token คือข้อมูลรายละเอียดของ Lexemes
result = 3 * number + 10;
Lexemes Tokens
result identifier
= equal_sign
number identifier
10 int_literal
* mult_op
+ plus_op
; semicolon
Lexical analysis เกี่ยวข้องกับการวิเคราะห์รูปแบบนิพจน์ Lexical analyzer คือ Pattern matcher หรือตัวแมชรูปแบบ ที่พยายามหา Substring ของสตริงซึ่งแมชกับรูปแบบสตริงที่กำหนด เช่น นิพจน์ result = 3 * number + 10; จะถูกนำไปวิเคราะห์ด้วย Lexical analysis เพื่อดูว่าภาษาสามารถสร้าง Substring ซึ่งแมชได้กับประโยคหรือไม่ ปกติแล้ว Lexical analyzer จะไม่สนใจ comment และ white space ต่างๆในโปรแกรม error ที่ตรวจพบในการวิเคราะห์ เช่น การกำหนดค่าคงที่ของ Floating point ที่ผิดรูปแบบของภาษา รูปแบบนิพจน์ เครื่องหมายต่างๆ ชื่อตัวแปร และค่าคงที่ ซึ่งจะต้องอาศัยตาราง Symbol table ช่วยในการวิเคราะห์
แนวทางในการพัฒนา Lexical analyzer ที่นิยมเช่น
1. การสร้าง Formal description ด้วยภาษาประเภท Descriptive language แล้วใช้เป็นเครื่องมือในการสร้าง Lexical analyzer
2. การออกแบบ State transition diagram แล้วทำการพัฒนาโปรแกรมตาม State transition diagram ที่ออกแบบ ซึ่งนิยมใช้ finite automata (P.193)
Syntax analysis เป็นการวิเคราะห์รูปแบบของภาษา ซึ่งกระบวนการที่เกี่ยวข้องเรียกว่า Parsing โดย Parser สามารถจำแนกได้ 2 ลักษณะตามทิศทางในการทำงานคือ top-down parser และ bottom-up parser
Top-down Parser สร้าง Parse tree ในลักษณะ preorder การ parse มีลักษณะซ้ายไปขวา โดยเยี่ยมโหนดทุกโหนดจาก root ไปยัง leaf ก่อนที่จะไปโหนดข้างเคียง (โหนดเพื่อนบ้าน)
กำหนด Production rules ต่อไปนี้
A → bB
A → cBb
A → a
พิจารณาประโยค xAz
Parser ต้องเลือกกฎที่น่าจะสร้างประโยคได้ โดยพิจารณาประโยคด้านซ้าย (LHS) ของ Production rule เป็นหลัก ในที่นี้อาจจะตัดสินใจเลือก A → a ซึ่งจะได้ xaz ซึ่งยังไม่แมชกับประโยค xAz อย่างไรก็ตาม Parser จะต้องเลือกใช้กฎอื่นๆจนครบหรือจนกว่าจะหาได้ ในตัวอย่างนี้ xbBz, xcBbz และ xaz เป็นผลลัพธ์จากการ parse ซึ่งไม่สามารถสร้างประโยคที่ต้องการได้เลย
Bottom-up Parser ทำการสร้าง Parse tree โดยดูอักขระในประโยคที่อยู่ด้านขวา (RHS) ของ Production rule แล้วแทนที่ด้วย LHS
S → aAc
A → aA | b
พิจารณาประโยค aabc
เมื่อดูที่ nonterminal symbol นั้น b มี nonterminal symbol ที่เกี่ยวข้องเพียงกฎเดียวดังนั้นจึงแทน LHS ของกฎในประโยค ได้ aaAc ขั้นตอนถัดไปดู RHS ที่แมชกับประโยคล่าสุดได้ aAc ต่อด้วย S ซึ่งเป็น Start symbol หรือท้ายที่สุดจะได้ Derivation สอดคล้องกับ
S => aAc => aaAc => aabc
ไวยากรณ์
<program> → begin <stmt_list> end
<stmt_list> → <stmt> | <stmt> ; <stmt_list>
<stmt> → <var> = <expression>
<var> → A | B | C
<expression> → <var> + <var> | <var> – <var> | <var>
ต้องการวิเคราะห์ว่า ประโยค begin A=B+C ; B = C end เป็นส่วนหนึ่งของภาษาหรือไม่
แสดงได้ด้วย Parse tree ดังนี้

หมายเลขกำกับแสดงลำดับของการสร้าง path ที่สร้างขึ้น จะเห็นว่าการสร้าง Parse tree ด้วย Top-down Parser จะพิจารณาในการต่อเติมพาธจากทางด้านซ้ายไปด้านขวา
อ้างอิง
[1] Robert W. Sebesta, "Concepts of Programming Languages", Pearson, 10th edition, 2013.
Thursday, July 16, 2015
Grammar และ Derivation
Grammar และ Derivation
ในการออกแบบภาษาการโปรแกรมคอมพิวเตอร์นั้น จะมีการกำหนดไวยากรณ์ (grammar) เพื่อสร้างรูปแบบ (syntax) ของภาษาทั้งหมด
ในภาษาที่มีการคอมไพล์ก็จะมีการทำ Syntax analysis ในเวลาคอมไพล์เพื่อตรวจดูว่าโปรแกรมที่เขียนนั้นถูกต้องตามภาษาหรือไม่ ส่วนภาษาที่ไม่มีการคอมไพล์หรือกลุ่มที่มีการนำไปใช้ในลักษณะ Interpretation จะมีการตรวจสอบ syntax ในเวลารันไทม์ กระบวนการในการวิเคราะห์ Syntax ของภาษาเพื่อดูว่าโปรแกรมที่เขียนนั้นเป็นไปตามรูปแบบที่กำหนดหรือไม่ สามารถกระทำได้ 2 วิธีคือใช้
1. Language Recognizers คือ device ซึ่งจะอ่านอักขระในเซตของอักขระทั้งหมดเข้ามาเรื่อยๆ แล้วพิจารณาว่าเป็นส่วนหนึ่งในภาษาหรือไม่ กลไกการทำงานนั้นอาจพิจารณาการทำงานเทียบเคียงกับภาษาไทยมี 44 ตัวอักษร มีวรรณยุกต์ 21 ตัว Recognizer จะทำการอ่านอักขระทั้งหมดเพื่อพิจารณาว่าเป็นประโยคภาษาไทยหรือไม่
ฉันอ่านหนังสือ
ด้หก่าหกสดาากสห่ด
ประธาน กิริยา กรรม
ฉัน อ่าน หนังสือ
การสร้างประโยคเพื่อตรวจสอบ syntax ของภาษาเรียกว่า Derivation
การทำ Derivation เพื่อสร้างประโยคของภาษาจะเริ่มจากการสร้างประโยคจาก Start symbol
Grammar:
<program> → begin <stmt_list> end
<stmt_list> → <stmt> | <stmt> ; <stmt_list>
<stmt> → <var> = <expression>
<var> → A | B | C
<expression> → <var> + <var> | <var> – <var> | <var>
ต้องการวิเคราะห์ว่า ประโยค begin A=B+C ; B = C end เป็นส่วนหนึ่งของภาษาหรือไม่
การทำ Derivation จะได้ดังนี้
<program> => begin <stmt_list> end
=> begin <stmt> ; <stmt_list> end
=> begin <var> = <expression> ; <stmt_list> end
=> begin A = <expression> ; <stmt_list> end
=> begin A = <var> + <var> ; <stmt_list> end
=> begin A = B + <var> ; <stmt_list> end
=> begin A = B + C ; <stmt_list> end
=> begin A = B + C ; <stmt> end
=> begin A = B + C ; <var> = <expression> end
=> begin A = B + C ; B = <expression> end
=> begin A = B + C ; B = <var> end
=> begin A = B + C ; B = C end
ดังนั้น Generator จะสรุปว่าประโยคนั้นเป็นส่วนหนึ่งของภาษา เพราะสามารสร้างประโยคได้
สิ่งจำเป็นในการทำ Derivation
1. ต้องกำหนดไวยากรณ์ ในไวยากรณ์ประกอบด้วย
- Start symbol เช่น <program> คือ start symbol
- Nonterminal symbol คือข้อความใน < > ซึ่งจะมี Production rule เกี่ยวข้องอย่างน้อย 1 rule
- Terminal symbol คือ lexeme หรือหน่วยเล็กที่สุดของภาษา
Production rule คือกฎในแต่ละบรรทัด
<program> → begin <stmt_list> end
<stmt_list> → <stmt> | <stmt> ; <stmt_list>
<stmt> → <var> = <expression>
<var> → A | B | C
<expression> → <var> + <var> | <var> – <var> | <var>
ในตัวอย่าง A, B และ C คือ Terminal symbol
ในการทำ Derivation นั้น การแทนที่ (replace) Nonterminal symbol ในแต่ละขั้นตอนนั้นจะต้องเลือกแทนที่ด้วย Production rule เพียงหนึ่ง Production rule เท่านั้น โดยนำประโยคในด้านขวามือไปแทนที่ Nonterminal symbol ของประโยคในขั้นตอนก่อนหน้า
จาก Derivation ด้านบน สามารถแสดงตำแหน่งที่แทนที่ (สีน้ำเงิน) ได้ดังนี้
<program> => begin <stmt_list> end
=> begin <stmt> ; <stmt_list> end
=> begin <var> = <expression> ; <stmt_list> end
=> begin A = <expression> ; <stmt_list> end
=> begin A = <var> + <var> ; <stmt_list> end
=> begin A = B + <var> ; <stmt_list> end
=> begin A = B + C ; <stmt_list> end
=> begin A = B + C ; <stmt> end
=> begin A = B + C ; <var> = <expression> end
=> begin A = B + C ; B = <expression> end
=> begin A = B + C ; B = <var> end
=> begin A = B + C ; B = C end
การแทนที่ในการทำ Derivation สามารถเลือกแทนที่ในตำแหน่งใดก็ได้ อย่างไรก็ตามอาจพิจารณาลักษณะการแทนที่ออกเป็น 2 ลักษณะคือ Left-most derivation (เช่นในตัวอย่าง) และ Right-most derivation
ในการออกแบบภาษาการโปรแกรมคอมพิวเตอร์นั้น จะมีการกำหนดไวยากรณ์ (grammar) เพื่อสร้างรูปแบบ (syntax) ของภาษาทั้งหมด
ในภาษาที่มีการคอมไพล์ก็จะมีการทำ Syntax analysis ในเวลาคอมไพล์เพื่อตรวจดูว่าโปรแกรมที่เขียนนั้นถูกต้องตามภาษาหรือไม่ ส่วนภาษาที่ไม่มีการคอมไพล์หรือกลุ่มที่มีการนำไปใช้ในลักษณะ Interpretation จะมีการตรวจสอบ syntax ในเวลารันไทม์ กระบวนการในการวิเคราะห์ Syntax ของภาษาเพื่อดูว่าโปรแกรมที่เขียนนั้นเป็นไปตามรูปแบบที่กำหนดหรือไม่ สามารถกระทำได้ 2 วิธีคือใช้
1. Language Recognizers คือ device ซึ่งจะอ่านอักขระในเซตของอักขระทั้งหมดเข้ามาเรื่อยๆ แล้วพิจารณาว่าเป็นส่วนหนึ่งในภาษาหรือไม่ กลไกการทำงานนั้นอาจพิจารณาการทำงานเทียบเคียงกับภาษาไทยมี 44 ตัวอักษร มีวรรณยุกต์ 21 ตัว Recognizer จะทำการอ่านอักขระทั้งหมดเพื่อพิจารณาว่าเป็นประโยคภาษาไทยหรือไม่
ฉันอ่านหนังสือ
ด้หก่าหกสดาากสห่ด
จากข้อความข้างต้นหาก Recognizer
อ่านจะค่อยๆอ่านอักขระเข้ามาซึ่ง ก็จะตอบได้ว่า ข้อความ "ฉันอ่านหนังสือ"
เป็นภาษาไทย ส่วนอีกข้อความหนึ่งไม่ใช่ภาษาไทย
2. Language Generators คือ device ซึ่งจะสร้างประโยคของภาษา สมมติว่าต้องการตรวจสอบภาษาไทยว่าประโยค "ฉันอ่านหนังสือ" เป็นภาษาไทยหรือไม่ ในการทำงาน Generator จะนำไวยากรณ์ของภาษาเข้ามาตรวจสอบ สมมติว่าไวยากรณ์ของภาษาไทยกำหนดไว้ว่า ประโยคจะต้องประกอบด้วยประธาน กิริยา และ กรรม ดังนั้น Generator จะพยายามสร้างประโยคซึ่งสอดคล้องกับรูปแบบในไวยากรณ์ ซึ่งประโยคสอดคล้องกับ Syntax ดังนั้นจะตัดสินได้ว่าประโยคนี้เป็นส่วนหนึ่งของภาษาประธาน กิริยา กรรม
ฉัน อ่าน หนังสือ
การสร้างประโยคเพื่อตรวจสอบ syntax ของภาษาเรียกว่า Derivation
การทำ Derivation เพื่อสร้างประโยคของภาษาจะเริ่มจากการสร้างประโยคจาก Start symbol
Grammar:
<program> → begin <stmt_list> end
<stmt_list> → <stmt> | <stmt> ; <stmt_list>
<stmt> → <var> = <expression>
<var> → A | B | C
<expression> → <var> + <var> | <var> – <var> | <var>
ต้องการวิเคราะห์ว่า ประโยค begin A=B+C ; B = C end เป็นส่วนหนึ่งของภาษาหรือไม่
การทำ Derivation จะได้ดังนี้
<program> => begin <stmt_list> end
=> begin <stmt> ; <stmt_list> end
=> begin <var> = <expression> ; <stmt_list> end
=> begin A = <expression> ; <stmt_list> end
=> begin A = <var> + <var> ; <stmt_list> end
=> begin A = B + <var> ; <stmt_list> end
=> begin A = B + C ; <stmt_list> end
=> begin A = B + C ; <stmt> end
=> begin A = B + C ; <var> = <expression> end
=> begin A = B + C ; B = <expression> end
=> begin A = B + C ; B = <var> end
=> begin A = B + C ; B = C end
ดังนั้น Generator จะสรุปว่าประโยคนั้นเป็นส่วนหนึ่งของภาษา เพราะสามารสร้างประโยคได้
สิ่งจำเป็นในการทำ Derivation
1. ต้องกำหนดไวยากรณ์ ในไวยากรณ์ประกอบด้วย
- Start symbol เช่น <program> คือ start symbol
- Nonterminal symbol คือข้อความใน < > ซึ่งจะมี Production rule เกี่ยวข้องอย่างน้อย 1 rule
- Terminal symbol คือ lexeme หรือหน่วยเล็กที่สุดของภาษา
Production rule คือกฎในแต่ละบรรทัด
<program> → begin <stmt_list> end
<stmt_list> → <stmt> | <stmt> ; <stmt_list>
<stmt> → <var> = <expression>
<var> → A | B | C
<expression> → <var> + <var> | <var> – <var> | <var>
ในตัวอย่าง A, B และ C คือ Terminal symbol
ในการทำ Derivation นั้น การแทนที่ (replace) Nonterminal symbol ในแต่ละขั้นตอนนั้นจะต้องเลือกแทนที่ด้วย Production rule เพียงหนึ่ง Production rule เท่านั้น โดยนำประโยคในด้านขวามือไปแทนที่ Nonterminal symbol ของประโยคในขั้นตอนก่อนหน้า
จาก Derivation ด้านบน สามารถแสดงตำแหน่งที่แทนที่ (สีน้ำเงิน) ได้ดังนี้
<program> => begin <stmt_list> end
=> begin <stmt> ; <stmt_list> end
=> begin <var> = <expression> ; <stmt_list> end
=> begin A = <expression> ; <stmt_list> end
=> begin A = <var> + <var> ; <stmt_list> end
=> begin A = B + <var> ; <stmt_list> end
=> begin A = B + C ; <stmt_list> end
=> begin A = B + C ; <stmt> end
=> begin A = B + C ; <var> = <expression> end
=> begin A = B + C ; B = <expression> end
=> begin A = B + C ; B = <var> end
=> begin A = B + C ; B = C end
การแทนที่ในการทำ Derivation สามารถเลือกแทนที่ในตำแหน่งใดก็ได้ อย่างไรก็ตามอาจพิจารณาลักษณะการแทนที่ออกเป็น 2 ลักษณะคือ Left-most derivation (เช่นในตัวอย่าง) และ Right-most derivation
Parameter passing mode
Parameter Passing Mode
โหมดการส่งผ่านค่าสู่พารามิเตอร์ (Parameter passing mode) ในการเขียนโปรแกรมภาษาใดๆก็ตาม เมื่อมีการสร้างฟังก์ชั่น ก็มักจะมีการส่งผ่านค่าเข้าสู่พารามิเตอร์ของฟังก์ชั่น การส่งผ่านค่านั้นโดยพื้นฐานจะมี 3 ลักษณะหรือโหมดการทำงานในการส่งผ่านค่าสู่พารามิเตอร์
1. in mode พารามิเตอร์ของฟังก์ชั่นรับค่าเข้าเพียงอย่างเดียว
2. out mode พารามิเตอร์ของฟังก์ชั่นไม่รับค่าเข้าแต่มีการส่งค่ากลับไปยังเออร์กูเมนต์ (ตัวแปรที่ส่งค่ามายังพารามิเตอร์ของฟังก์ชั่น)
3. inout mode พารามิเตอร์ของฟังก์ชั่นรับค่าเข้าและส่งค่ากลับไปยังเออร์กูเมนต์
ฟังก์ชั่นหนึ่งๆ อาจมีหลายพารามิเตอร์ และแต่ละพารามิเตอร์อาจทำงานด้วยโหมดที่แตกต่างกันก็ได้
ภาษาการโปรแกรมหนึ่งๆ เลือกออกแบบโหมดในการส่งผ่านค่าสู่พารามิเตอร์ที่แตกต่างกัน โหมดที่สร้างปัญหาได้มากที่สุดคือโหมด inout mode จะได้ยกตัวอย่างต่อไป
ที่บรรยายมานี้ยังไม่เกี่ยวข้องกับการส่งพารามิเตอร์ Passing by value, Passing by reference ขออธิบายการทำงานของพารามิเตอร์ในแต่ละโหมดก่อน

ในหลักการการโปรแกรม Actual parameter คือค่าจริงที่จะถูกส่งให้กับพารามิเตอร์ในฟังก์ชั่น หรือ Formal parameter ซึ่ง Formal parameter พารามิเตอร์ที่ประกาศในฟังก์ชัน
ภาษาการโปรแกรมอาจสนับสนุนทั้ง 3 โหมด
int a = 5, b = 10, c = 15;
myfunction(a, b, &c);
....
void myfunction(int x, int y, int *z){
x = x +10;
y = y + 5;
*z = *z + 20;
printf("%d %d %d", x, y, *z);
}
จากโค้ดด้านบนพารามิเตอร์ x และ y ทำงานในโหมด in mode ส่วน z ทำงานในโหมด inout mode เพราะการแก้ไขค่าที่พอยน์เตอร์ z ชี้อยู่จะถูกนำไปสำเนาให้กับ Actual parameter c ซึ่งมีค่าเท่ากับ 35 ส่วน a และ b ยังคงมีค่าเท่ากับ 5 และ 10 ตามลำดับ
สมมติให้โค้ดมาตามนี้
int a = 10, b = 20;
void myfunction(int *x, int *y){
*x = *x +10;
*y = *y + 5;
printf("%d %d ", x, y);

โหมดการส่งผ่านค่าสู่พารามิเตอร์ (Parameter passing mode) ในการเขียนโปรแกรมภาษาใดๆก็ตาม เมื่อมีการสร้างฟังก์ชั่น ก็มักจะมีการส่งผ่านค่าเข้าสู่พารามิเตอร์ของฟังก์ชั่น การส่งผ่านค่านั้นโดยพื้นฐานจะมี 3 ลักษณะหรือโหมดการทำงานในการส่งผ่านค่าสู่พารามิเตอร์
1. in mode พารามิเตอร์ของฟังก์ชั่นรับค่าเข้าเพียงอย่างเดียว
2. out mode พารามิเตอร์ของฟังก์ชั่นไม่รับค่าเข้าแต่มีการส่งค่ากลับไปยังเออร์กูเมนต์ (ตัวแปรที่ส่งค่ามายังพารามิเตอร์ของฟังก์ชั่น)
3. inout mode พารามิเตอร์ของฟังก์ชั่นรับค่าเข้าและส่งค่ากลับไปยังเออร์กูเมนต์
ฟังก์ชั่นหนึ่งๆ อาจมีหลายพารามิเตอร์ และแต่ละพารามิเตอร์อาจทำงานด้วยโหมดที่แตกต่างกันก็ได้
ภาษาการโปรแกรมหนึ่งๆ เลือกออกแบบโหมดในการส่งผ่านค่าสู่พารามิเตอร์ที่แตกต่างกัน โหมดที่สร้างปัญหาได้มากที่สุดคือโหมด inout mode จะได้ยกตัวอย่างต่อไป
ที่บรรยายมานี้ยังไม่เกี่ยวข้องกับการส่งพารามิเตอร์ Passing by value, Passing by reference ขออธิบายการทำงานของพารามิเตอร์ในแต่ละโหมดก่อน

ในหลักการการโปรแกรม Actual parameter คือค่าจริงที่จะถูกส่งให้กับพารามิเตอร์ในฟังก์ชั่น หรือ Formal parameter ซึ่ง Formal parameter พารามิเตอร์ที่ประกาศในฟังก์ชัน
ภาษาการโปรแกรมอาจสนับสนุนทั้ง 3 โหมด
int a = 5, b = 10, c = 15;
myfunction(a, b, &c);
....
void myfunction(int x, int y, int *z){
x = x +10;
y = y + 5;
*z = *z + 20;
printf("%d %d %d", x, y, *z);
}
จากโค้ดด้านบนพารามิเตอร์ x และ y ทำงานในโหมด in mode ส่วน z ทำงานในโหมด inout mode เพราะการแก้ไขค่าที่พอยน์เตอร์ z ชี้อยู่จะถูกนำไปสำเนาให้กับ Actual parameter c ซึ่งมีค่าเท่ากับ 35 ส่วน a และ b ยังคงมีค่าเท่ากับ 5 และ 10 ตามลำดับ
สมมติให้โค้ดมาตามนี้
int a = 10, b = 20;
myanotherfunc(&a, &a);
....void myfunction(int *x, int *y){
*x = *x +10;
*y = *y + 5;
printf("%d %d ", x, y);
}
จะเห็นว่า Actual parameter คือ a ส่วน Formal parameter คือพอยน์เตอร์ x และ y ซึ่งชี้ไปยังตำแหน่งในเมมโมรีตำแหน่งเดียวกัน และ Formal parameter x และ y ทำงานใน inout mode ซึ่งจะรับค่าเข้าและส่งกลับ
คำถามคือถ้าหากมีการส่ง Actual parameter เข้าสู่ฟังก์ชั่น ผลลัพธ์ที่จะถูกส่งกลับคืออะไร ?
หากโปรแกรมเมอร์พิจารณาดูตามโค้ด ก็อาจจะตอบว่า 20 หรือ 15
พิจารณาการใช้งานเมมโมรีกับพอยน์เตอร์ พารามิเตอร์ในฟังก์ชั่นจะถูกจองพื้นที่ในส่วนของ x และ y แต่สำเนาค่าจากตำแหน่งของตัวแปร a ซึ่งมีค่าเท่ากับ 10 (ภาพบน) ถ้าการจับคู่ของ Actual และ Formal parameter จากซ้ายไปขวา (ภาพบนซ้าย) พารามิเตอร์ y จะอยู่ top of stack แล้วเมื่อมีการส่งค่ากลับหลังจากประเมินผลนิพจน์ ค่าของพารามิเตอร์ x จะถูกส่งไปทีหลัง ซึ่งจะทำให้ a มีค่าเท่ากับ 20
ในทางกลับกัน ถ้าการจับคู่ทำจากขวาไปซ้าย พารามิเตอร์ x จะอยู่ top of stack แล้ว a จะมีค่าเป็น 15 เนื่องจากพารามิเตอร์ y จะถูกส่งไปทีหลัง (ภาพบนขวา)

ในภาษาการโปรแกรมที่มีการออกแบบ จะกำหนดลักษณะการส่งค่าเออร์กูเมนต์สู่พารามิเตอร์ เป็นลักษณะต่างๆ เช่น
- Pass-by-value มีการทำสำเนาค่าของ Actual parameter ให้กับ Formal parameter หรือเป็นการส่งค่าแบบ in mode
- Pass-by-result ไม่มีการสำเนาค่าของ Actual parameter ให้กับ Formal parameter แต่มีการรีเทิร์นค่ากลับจาก Formal parameter ให้กับ Actual parameter หรือเป็นการส่งค่าแบบ out mode การส่งลักษณะนี้มีในภาษา C#
- Pass-by-value-result มีการทำสำเนาค่าจาก Actual parameter ให้กับ Formal parameter และมีการส่งค่ากลับจาก Formal parameter ให้กับ Actual parameter หรือเป็นการส่งในลักษณะ inout mode (ดังตัวอย่างด้านบน)
- Pass-by-reference ไม่มีการสำเนาค่าของ Actual parameter ให้กับ Formal parameter แต่ส่ง Access path (ตำแหน่งของ Actual) ให้กับ Formal parameter ซึ่งจะเกิดปัญหา Aliasing เมื่อระหว่างการทำงานภายในฟังก์ชั่นมีการอ้างอิง Nonlocal variable (ตัวแปรที่อยู่นอกฟังก์ชั่น) ในภาษา C++ มีการใช้งานในลักษณะนี้ เช่น void fun(int &first, int &second) เป็นการประกาศพารามิเตอร์ในลักษณะ inout mode ซึ่งสามารถเรียกฟังก์ชั่นเช่น fun (a, b) ซึ่งตัวแปร first และ second จะอ้างอิงตำแหน่งในเมมโมรีของ a และ b โดยไม่มีการสำเนาค่าไว้ในเมมโมรีของฟังก์ชั่น
- Pass-by-name มีการส่งผ่านค่าในลักษณะ inout mode แต่ไม่เกี่ยวข้องกับลำดับการจับคู่ของ Actual parameter และ Formal parameter ขึ้นกับการ execute นิพจน์ในฟังก์ชั่น การทำงานในลักษณะนี้มีภาษาการโปรแกรมไม่มากนักที่สนับสนุน
โดยสรุป
ในการใช้งาน inout parameter passing mode นั้น จำเป็นที่จะต้องพิจารณาลำดับในการเข้าคู่ของ Actual parameter และ Formal parameter เนื่องจากจะสัมพันธ์กับการรีเทิร์นค่ากลับ ซึ่งการรีเทิร์นค่ากลับนั้นพิจารณาจาก Stack ของ function
แบบฝึกหัด
1. ถ้ากำหนดการส่งค่าเข้าสู่ฟังก์ชั่น
fun(list[i], list[j])
void fun(int &first, int &second){
..
}
เป็นแบบ Pass-by-reference โดย i และ j มีค่าเท่ากัน จะเกิดปัญหา Aliasing หรือไม่?
2. ถ้ากำหนด
fun1(list[i], list)
แบบฝึกหัด
1. ถ้ากำหนดการส่งค่าเข้าสู่ฟังก์ชั่น
fun(list[i], list[j])
void fun(int &first, int &second){
..
}
เป็นแบบ Pass-by-reference โดย i และ j มีค่าเท่ากัน จะเกิดปัญหา Aliasing หรือไม่?
2. ถ้ากำหนด
fun1(list[i], list)
void fun(int &first, int &second){
..
}
..
}
first และ second จะเป็น Alias หรือไม่ ?
Wednesday, July 15, 2015
Aliasing และ Dangling Reference
Aliasing และ Dangling Reference
Aliasing คือ การอ้างอิงไปยังเมมโมรีตำแหน่งหนึ่ง ที่สามารถกระทำได้ด้วยตัวแปร (identifier) มากกว่า 1 ตัวแปรขึ้นไป
ปัญหา Aliasing มักเกิดจากการใช้งานพอยน์เตอร์โดยไม่ระวัง หากไม่เข้าใจก็จะทำให้เสียเวลาหา bug ในโปรแกรมมากขึ้นเช่น
จากโค้ด
บรรทัดที่ 5 พอยน์เตอร์ b จะชี้ไปยังตำแหน่งที่ตัวแปร a อยู่
บรรทัดที่ 6 เมื่อ a มีค่าเท่ากับ 20 ก็พลอยทำให้ค่าที่พอยน์เตอร์ b ชี้คือ 20
บรรทัดที่ 7 แสดงผลลัพธ์จะได้ผลลัพธืเหมือนกันคือ a = 20 คือของพอยน์เตอร์ b ชี้ไปคือ 20 เช่นกัน
บรรทัดที่ 8 ค่าที่พอยน์เตอร์ชี้ ในที่นี้ยังอยู่ตำแหน่งเดิมคือตำแหน่งที่ a อยู่ ถูกแก้ไขเป็น 30
บรรทัดที่ 9 แสดงผลลัพธ์จะได้ผลลัพธืเหมือนกันคือ a = 20 คือของพอยน์เตอร์ b ชี้ไปคือ 30 เช่นกัน
จะเห็นว่าโปรแกรมเมอร์ต้องเข้าใจว่าเมื่อมีการแก้ไขค่าของ a หรือ ค่าที่พอยน์เตอร์อ้างอิงจะมีผลกระทบต่อกันเสมอ
สมมติว่าโปรแกรมเมอร์เขียนโปรแกรมถึงบรรทัดที่ 10 จะเข้าใจว่า a = 20 ตามโค้ดที่ตัวเองเขียน ซึ่งอันที่จริงแล้ว a ถูกแก้ไปเป็น 30 แล้วจาดบรรทัดที่ 8 ดังนั้นผลลัพธ์ที่เกิดขึ้นคือ a = 110 ไม่ใช่ a = 100 ตามที่ตนเองเข้าใจจากการอ่านโค้ด
Dangling Reference
Dangling Reference คือปัญหาที่เกิดจากการใช้งานพอยน์เตอร์ทั้งที่ตำแหน่งที่พอยน์เตอร์ชี้นั้นไม่มีอยู่แล้วในเมมโมรี ปัญหานี้สืบเนื่องต่อจาก Aliasing นั่นเอง
เช่น
บรรทัดที่ 4 พอยน์เตอร์ b จะชี้ไปที่ตำแหน่งที่ตัวแปร a อยู่ในเมมโมรี
บรรทัดที่ 5 เมื่อกำหนด a = 20 จะมีผลต่อค่าข้อมูลที่พอยน์เตอร์ชี้ตามไปด้วย
บรรทัดที่ 6 ทั้ง a และ *b ค่าเท่ากันคือ 20 และมีตำแหน่งในเมมโมรีที่อ้างอิงเป็นตำแหน่งเดียวกัน
บรรทัดที่ 7 กำหนด Null pointer คือลบการอ้างอิงของพอยน์เตอร์ออกไป หรือพอยน์เตอร์ b ณ ขณะนี้ไม่ได้อ้างอิงไปยังเมมโมรีอีกแล้ว
บรรทัดที่ 8 ค่าที่พอยน์เตอร์ b ชี้ (*b) คือ 0 และไม่มีตำแหน่งที่พอยน์เตอร์ชี้อีกแล้ว ตำแหน่งของ a ยังอยู่ที่เดิม แต่ตำแหน่งของ b ไม่มีแล้ว
บรรทัดที่ 9 การกำหนดค่าที่พอยน์เตอร์ชี้ *b = 40 จะเกิด Error คือ Non pointer reference ถึงแม้ว่าบรรทัดที่ 10 *b จะมีค่าเป็น 40 แต่ตำแหน่งของ b ไม่มีแล้ว และการแก้ไขค่าผ่านพอยน์เตอร์ b ไม่มีผลต่อพอยน์เตอร์ a ดังนั้น a ยังเป็น 20 (ค่าที่แก้ไขล่าสุดในบรรทัดที่ 5)
Aliasing คือ การอ้างอิงไปยังเมมโมรีตำแหน่งหนึ่ง ที่สามารถกระทำได้ด้วยตัวแปร (identifier) มากกว่า 1 ตัวแปรขึ้นไป
ปัญหา Aliasing มักเกิดจากการใช้งานพอยน์เตอร์โดยไม่ระวัง หากไม่เข้าใจก็จะทำให้เสียเวลาหา bug ในโปรแกรมมากขึ้นเช่น
1. | int a;
2. | int *b;
3. | a = 10;
4. | b = &a;
5. | a = 20;
6. | printf (“%d %d\n”, a, *b);
7. | *b = 30;
8. | printf (“%d %d”, a, *b);
9. | a = a + 80;
|
จากโค้ด
บรรทัดที่ 5 พอยน์เตอร์ b จะชี้ไปยังตำแหน่งที่ตัวแปร a อยู่
บรรทัดที่ 6 เมื่อ a มีค่าเท่ากับ 20 ก็พลอยทำให้ค่าที่พอยน์เตอร์ b ชี้คือ 20
บรรทัดที่ 7 แสดงผลลัพธ์จะได้ผลลัพธืเหมือนกันคือ a = 20 คือของพอยน์เตอร์ b ชี้ไปคือ 20 เช่นกัน
บรรทัดที่ 8 ค่าที่พอยน์เตอร์ชี้ ในที่นี้ยังอยู่ตำแหน่งเดิมคือตำแหน่งที่ a อยู่ ถูกแก้ไขเป็น 30
บรรทัดที่ 9 แสดงผลลัพธ์จะได้ผลลัพธืเหมือนกันคือ a = 20 คือของพอยน์เตอร์ b ชี้ไปคือ 30 เช่นกัน
จะเห็นว่าโปรแกรมเมอร์ต้องเข้าใจว่าเมื่อมีการแก้ไขค่าของ a หรือ ค่าที่พอยน์เตอร์อ้างอิงจะมีผลกระทบต่อกันเสมอ
สมมติว่าโปรแกรมเมอร์เขียนโปรแกรมถึงบรรทัดที่ 10 จะเข้าใจว่า a = 20 ตามโค้ดที่ตัวเองเขียน ซึ่งอันที่จริงแล้ว a ถูกแก้ไปเป็น 30 แล้วจาดบรรทัดที่ 8 ดังนั้นผลลัพธ์ที่เกิดขึ้นคือ a = 110 ไม่ใช่ a = 100 ตามที่ตนเองเข้าใจจากการอ่านโค้ด
Dangling Reference
Dangling Reference คือปัญหาที่เกิดจากการใช้งานพอยน์เตอร์ทั้งที่ตำแหน่งที่พอยน์เตอร์ชี้นั้นไม่มีอยู่แล้วในเมมโมรี ปัญหานี้สืบเนื่องต่อจาก Aliasing นั่นเอง
เช่น
1. | int a;
2. | int *b;
3. | a = 10;
4. | b = &a;
5. | a = 20;
6. | printf (“a=%d b=%d a_addr =
%x b_addr = %x \n”, a, *b, &a, b);
7. | b = NULL; //pointer b points to nothing.
8. | printf (“a=%d b=%d a_addr =
%x b_addr = %x ”, a, *b, &a, b);
9. | *b = 40; //Dangling reference
10.| printf (“a=%d b=%d a_addr = %x b_addr = %x ”, a, *b, &a, b);
|
บรรทัดที่ 4 พอยน์เตอร์ b จะชี้ไปที่ตำแหน่งที่ตัวแปร a อยู่ในเมมโมรี
บรรทัดที่ 5 เมื่อกำหนด a = 20 จะมีผลต่อค่าข้อมูลที่พอยน์เตอร์ชี้ตามไปด้วย
บรรทัดที่ 6 ทั้ง a และ *b ค่าเท่ากันคือ 20 และมีตำแหน่งในเมมโมรีที่อ้างอิงเป็นตำแหน่งเดียวกัน
บรรทัดที่ 7 กำหนด Null pointer คือลบการอ้างอิงของพอยน์เตอร์ออกไป หรือพอยน์เตอร์ b ณ ขณะนี้ไม่ได้อ้างอิงไปยังเมมโมรีอีกแล้ว
บรรทัดที่ 8 ค่าที่พอยน์เตอร์ b ชี้ (*b) คือ 0 และไม่มีตำแหน่งที่พอยน์เตอร์ชี้อีกแล้ว ตำแหน่งของ a ยังอยู่ที่เดิม แต่ตำแหน่งของ b ไม่มีแล้ว
บรรทัดที่ 9 การกำหนดค่าที่พอยน์เตอร์ชี้ *b = 40 จะเกิด Error คือ Non pointer reference ถึงแม้ว่าบรรทัดที่ 10 *b จะมีค่าเป็น 40 แต่ตำแหน่งของ b ไม่มีแล้ว และการแก้ไขค่าผ่านพอยน์เตอร์ b ไม่มีผลต่อพอยน์เตอร์ a ดังนั้น a ยังเป็น 20 (ค่าที่แก้ไขล่าสุดในบรรทัดที่ 5)
Subscribe to:
Comments (Atom)